Concurrency describes the concept of running several tasks at the same time. This can either happen in a time-shared manner on a single CPU core, or truly in parallel if multiple CPU cores are available.
OS X and iOS provide several different APIs to enable concurrent programming. Each of these APIs has different capabilities and limitations, making them suitable for different tasks. They also sit on very different levels of abstraction. We have the possibility to operate very close to the metal, but this also comes with great responsibility to get things right.
Concurrent programming is a very difficult subject with many intricate problems and pitfalls, and it's easy to forget this while using APIs like Grand Central Dispatch or NSOperationQueue. This article will first give an overview of the different concurrency APIs on OS X and iOS, and then dive deeper into the inherent challenges of concurrent programming, which are independent of the specific API you use.
Concurrency APIs on OS X and iOS
Apple's mobile and desktop operating systems provide the same APIs for concurrent programming. In this article we are going to take a look at pthread and NSThread, Grand Central Dispatch, NSOperationQueue, and NSRunLoop. Technically, run loops are the odd ones out in this list, because they don't enable true parallelism. But they are related closely enough to the topic that it's worth having a closer look.
We'll start with the lower-level APIs and move our way up to the higher-level ones. We chose this route because the higher-level APIs are built on top of the lower-level APIs. However, when choosing an API for your use case, you should consider them in the exact opposite order: choose the highest level abstraction that gets the job done and keep your concurrency model very simple.
If you're wondering why we are so persistent recommending high-level abstractions and very simple concurrency code, you should read the second part of this article, challenges of concurrent programming, as well as Peter Steinberger's thread safety article.
Threads
Threads are subunits of processes, which can be scheduled independently by the operating system scheduler. Virtually all concurrency APIs are built on top of threads under the hood -- that's true for both Grand Central Dispatch and operation queues.
Multiple threads can be executed at the same time on a single CPU core (or at least perceived as at the same time). The operating system assigns small slices of computing time to each thread, so that it seems to the user as if multiple tasks are executed at the same time. If multiple CPU cores are available, then multiple threads can be executed truly in parallel, therefore lessening the total time needed for a certain workload.
You can use the CPU strategy view in Instruments to get some insight of how your code or the framework code you're using gets scheduled for execution on multiple CPU cores.
The important thing to keep in mind is that you have no control over where and when your code gets scheduled, and when and for how long its execution will be paused in order for other tasks to take their turn. This kind of thread scheduling is a very powerful technique. However, it also comes with great complexity, which we will investigate later on.
Leaving this complexity aside for a moment, you can either use the POSIX thread API, or the Objective-C wrapper around this API, NSThread, to create your own threads. Here's a small sample that finds the minimum and maximum in a set of 1 million numbers using pthread. It spawns off 4 threads that run in parallel. It should be obvious from this example why you wouldn't want to use pthreads directly.
#import <pthread.h>
struct threadInfo {
uint32_t * inputValues;
size_t count;
};
struct threadResult {
uint32_t min;
uint32_t max;
};
void * findMinAndMax(void *arg)
{
struct threadInfo const * const info = (struct threadInfo *) arg;
uint32_t min = UINT32_MAX;
uint32_t max = 0;
for (size_t i = 0; i < info->count; ++i) {
uint32_t v = info->inputValues[i];
min = MIN(min, v);
max = MAX(max, v);
}
free(arg);
struct threadResult * const result = (struct threadResult *) malloc(sizeof(*result));
result->min = min;
result->max = max;
return result;
}
int main(int argc, const char * argv[])
{
size_t const count = 1000000;
uint32_t inputValues[count];
// Fill input values with random numbers:
for (size_t i = 0; i < count; ++i) {
inputValues[i] = arc4random();
}
// Spawn 4 threads to find the minimum and maximum:
size_t const threadCount = 4;
pthread_t tid[threadCount];
for (size_t i = 0; i < threadCount; ++i) {
struct threadInfo * const info = (struct threadInfo *) malloc(sizeof(*info));
size_t offset = (count / threadCount) * i;
info->inputValues = inputValues + offset;
info->count = MIN(count - offset, count / threadCount);
int err = pthread_create(tid + i, NULL, &findMinAndMax, info);
NSCAssert(err == 0, @"pthread_create() failed: %d", err);
}
// Wait for the threads to exit:
struct threadResult * results[threadCount];
for (size_t i = 0; i < threadCount; ++i) {
int err = pthread_join(tid[i], (void **) &(results[i]));
NSCAssert(err == 0, @"pthread_join() failed: %d", err);
}
// Find the min and max:
uint32_t min = UINT32_MAX;
uint32_t max = 0;
for (size_t i = 0; i < threadCount; ++i) {
min = MIN(min, results[i]->min);
max = MAX(max, results[i]->max);
free(results[i]);
results[i] = NULL;
}
NSLog(@"min = %u", min);
NSLog(@"max = %u", max);
return 0;
}
NSThread is a simple Objective-C wrapper around pthreads. This makes the code look more familiar in a Cocoa environment. For example, you can define a thread as a subclass of NSThread, which encapsulates the code you want to run in the background. For the previous example, we could define an NSThread subclass like this:
@interface FindMinMaxThread : NSThread
@property (nonatomic) NSUInteger min;
@property (nonatomic) NSUInteger max;
- (instancetype)initWithNumbers:(NSArray *)numbers;
@end
@implementation FindMinMaxThread {
NSArray *_numbers;
}
- (instancetype)initWithNumbers:(NSArray *)numbers
{
self = [super init];
if (self) {
_numbers = numbers;
}
return self;
}
- (void)main
{
NSUInteger min;
NSUInteger max;
// process the data
self.min = min;
self.max = max;
}
@end
To start new threads, we need to create new thread objects and call their start methods:
NSMutableSet *threads = [NSMutableSet set];
NSUInteger numberCount = self.numbers.count;
NSUInteger threadCount = 4;
for (NSUInteger i = 0; i < threadCount; i++) {
NSUInteger offset = (numberCount / threadCount) * i;
NSUInteger count = MIN(numberCount - offset, numberCount / threadCount);
NSRange range = NSMakeRange(offset, count);
NSArray *subset = [self.numbers subarrayWithRange:range];
FindMinMaxThread *thread = [[FindMinMaxThread alloc] initWithNumbers:subset];
[threads addObject:thread];
[thread start];
}
Now we could observe the threads' isFinished property to detect when all our newly spawned threads have finished before evaluating the result. We will leave this exercise to the interested reader though. The main point is that working directly with threads, using either the pthread or the NSThread APIs, is a relatively clunky experience and doesn't fit our mental model of coding very well.
One problem that can arise from directly using threads is that the number of active threads increases exponentially if both your code and underlying framework code spawn their own threads. This is actually a quite common problem in big projects. For example, if you create eight threads to take advantage of eight CPU cores, and the framework code you call into from these threads does the same (as it doesn't know about the threads you already created), you can quickly end up with dozens or even hundreds of threads. Each part of the code involved acted responsibly in itself; nevertheless, the end result is problematic. Threads don't come for free. Each thread ties up memory and kernel resources.
Next up, we'll discuss two queue-based concurrency APIs: Grand Central Dispatch and operation queues. They alleviate this problem by centrally managing a thread pool that everybody uses collaboratively.
Grand Central Dispatch
Grand Central Dispatch (GCD) was introduced in OS X 10.6 and iOS 4 in order to make it easier for developers to take advantage of the increasing numbers of CPU cores in consumer devices. We will go into more detail about GCD in our article about low-level concurrency APIs.
With GCD you don't interact with threads directly anymore. Instead you add blocks of code to queues, and GCD manages a thread pool behind the scenes. GCD decides on which particular thread your code blocks are going to be executed on, and it manages these threads according to the available system resources. This alleviates the problem of too many threads being created, because the threads are now centrally managed and abstracted away from application developers.
The other important change with GCD is that you as a developer think about work items in a queue rather than threads. This new mental model of concurrency is easier to work with.
GCD exposes five different queues: the main queue running on the main thread, three background queues with different priorities, and one background queue with an even lower priority, which is I/O throttled. Furthermore, you can create custom queues, which can either be serial or concurrent queues. While custom queues are a powerful abstraction, all blocks you schedule on them will ultimately trickle down to one of the system's global queues and its thread pool(s).
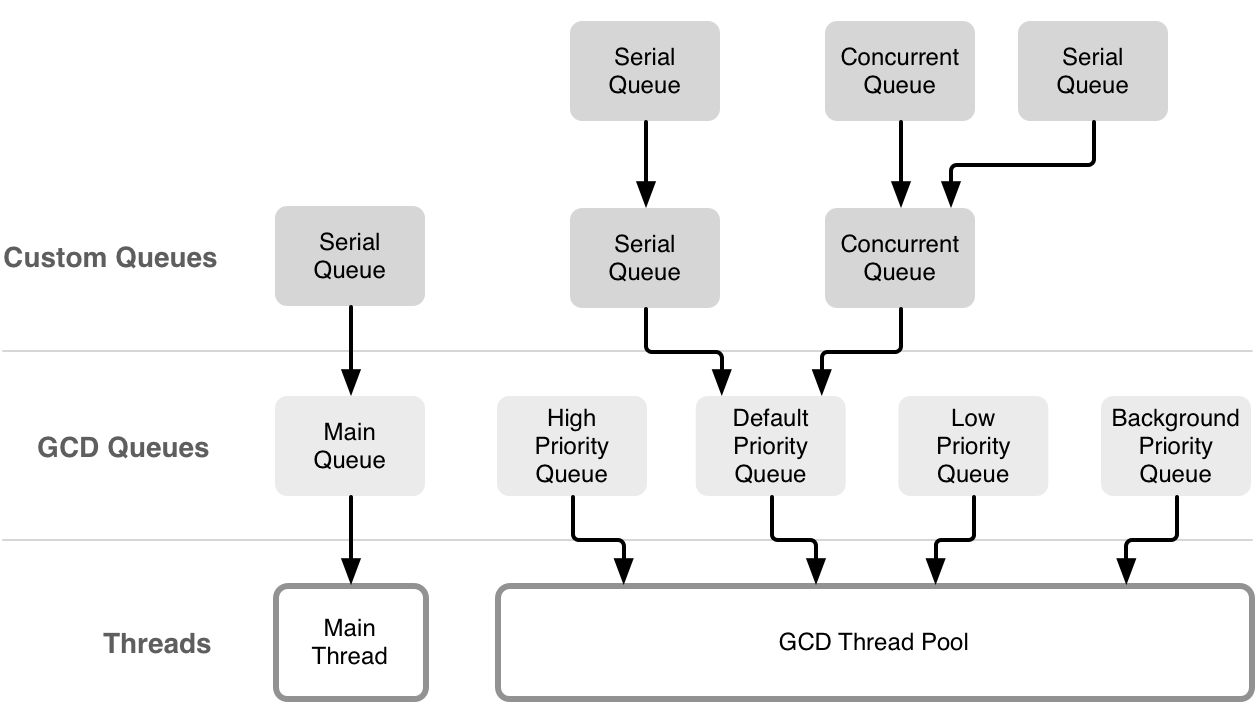
Making use of several queues with different priorities sounds pretty straightforward at first. However, we strongly recommend that you use the default priority queue in almost all cases. Scheduling tasks on queues with different priorities can quickly result in unexpected behavior if these tasks access shared resources. This can lead as far as causing your whole program to come to a grinding halt because some low-priority tasks are blocking a high-priority task from executing. You can read more about this phenomenon, called priority inversion, below.
Although GCD is a low-level C API, it's pretty straightforward to use. This makes it easy to forget that all caveats and pitfalls of concurrent programming still apply while dispatching blocks onto GCD queues. Please make sure to read about the challenges of concurrent programming below, in order to be aware of the potential problems. Furthermore, we have an excellent walkthrough of the GCD API in this issue that contains many in-depth explanations and valuable hints.
Operation Queues
Operation queues are a Cocoa abstraction of the queue model exposed by GCD. While GCD offers more low-level control, operation queues implement several convenient features on top of it, which often makes it the best and safest choice for application developers.
The NSOperationQueue class has two different types of queues: the main queue and custom queues. The main queue runs on the main thread, and custom queues are processed in the background. In any case, the tasks which are processed by these queues are represented as subclasses of NSOperation.
You can define your own operations in two ways: either by overriding main, or by overriding start. The former is very simple to do, but gives you less flexibility. In return, the state properties like isExecuting and isFinished are managed for you, simply by assuming that the operation is finished when main returns.
@implementation YourOperation
- (void)main
{
// do your work here ...
}
@end
If you want more control and to maybe execute an asynchronous task within the operation, you can override start:
@implementation YourOperation
- (void)start
{
self.isExecuting = YES;
self.isFinished = NO;
// start your work, which calls finished once it's done ...
}
- (void)finished
{
self.isExecuting = NO;
self.isFinished = YES;
}
@end
Notice that in this case, you have to manage the operation's state manually. In order for an operation queue to be able to pick up a such a change, the state properties have to be implemented in a KVO-compliant way. So make sure to send proper KVO messages in case you don't set them via default accessor methods.
In order to benefit from the cancelation feature exposed by operation queues, you should regularly check the isCancelled property for longer-running operations:
- (void)main
{
while (notDone && !self.isCancelled) {
// do your processing
}
}
Once you have defined your operation class, it's very easy to add an operation to a queue:
NSOperationQueue *queue = [[NSOperationQueue alloc] init];
YourOperation *operation = [[YourOperation alloc] init];
[queue addOperation:operation];
Alternatively, you can also add blocks to operation queues. This comes in handy, e.g. if you want to schedule one-off tasks on the main queue:
[[NSOperationQueue mainQueue] addOperationWithBlock:^{
// do something...
}];
While this is a very convenient way of scheduling work onto a queue, defining your own NSOperation subclasses can be very helpful during debugging. If you override the operation's description method, you can easily identify all the operations currently scheduled in a certain queue.
Beyond the basics of scheduling operations or blocks, operation queues offer some features which would be non-trivial to get right in GCD. For example, you can easily control how many operations of a certain queue may be executed concurrently with the maxConcurrentOperationCount property. Setting it to one gives you a serial queue, which is great for isolation purposes.
Another convenient feature is the sorting of operations within a queue according to their priorities. This is not the same as GCD's queue priorities. It solely influences the execution order of all operations scheduled in one queue. If you need more control over the sequence of execution beyond the five standard priorities, you can specify dependencies between operations like this:
[intermediateOperation addDependency:operation1];
[intermediateOperation addDependency:operation2];
[finishedOperation addDependency:intermediateOperation];
This simple code guarantees that operation1 and operation2 will be executed before intermediateOperation, which, in turn, will be executed before finishedOperation. Operation dependencies are a very powerful mechanism to specify a well-defined execution order. This lets you create things like operation groups, which are guaranteed to be executed before the dependent operation, or serial operations within an otherwise concurrent queue.
By the very nature of abstractions, operation queues come with a small performance hit compared to using the GCD API. However, in almost all cases, this impact is negligible and operation queues are the tool of choice.
Run Loops
Run loops are not technically a concurrency mechanism like GCD or operation queues, because they don't enable the parallel execution of tasks. However, run loops tie in directly with the execution of tasks on the main dispatch/operation queue and they provide a mechanism to execute code asynchronously.
Run loops can be a lot easier to use than operation queues or GCD, because you don't have to deal with the complexity of concurrency and still get to do things asynchronously.
A run loop is always bound to one particular thread. The main run loop associated with the main thread has a central role in each Cocoa and CocoaTouch application, because it handles UI events, timers, and other kernel events. Whenever you schedule a timer, use a NSURLConnection. or call performSelector:withObject:afterDelay:, the run loop is used behind the scenes in order to perform these asynchronous tasks.
Whenever you use a method which relies on the run loop, it is important to remember that run loops can be run in different modes. Each mode defines a set of events the run loop is going to react to. This is a clever way to temporarily prioritize certain tasks over others in the main run loop.
A typical example of this is scrolling on iOS. While you're scrolling, the run loop is not running in its default mode, and therefore, it's not going to react to, for example, a timer you have scheduled before. Once scrolling stops, the run loop returns to the default mode and the events which have been queued up are executed. If you want a timer to fire during scrolling, you need to add it to the run loop in the NSRunLoopCommonModes mode.
The main thread always has the main run loop set up and running. Other threads though don't have a run loop configured by default. You can set up a run loop for other threads too, but you will rarely need to do this. Most of the time it is much easier to use the main run loop. If you need to do heavier work that you don't want to execute on the main thread, you can still dispatch it onto another queue after your code is called from the main run loop. Chris has some good examples of this pattern in his article about common background practices.
If you really need to set up a run loop on another thread, don't forget to add at least one input source to it. If a run loop has no input sources configured, every attempt to run it will exit immediately.
Challenges of Concurrent Programming
Writing concurrent programs comes with many pitfalls. As soon as you're doing more than the most basic things, it becomes difficult to oversee all the different states in the interplay of multiple tasks being executed in parallel. Problems can occur in a non-deterministic way, which makes it even more difficult to debug concurrent code.
There is a prominent example for unforeseen behavior of concurrent programs: In 1995, NASA sent the Pathfinder mission to Mars. Not too long after a successful landing on our red neighboring planet, the mission almost came to an abrupt end. The Mars rover kept rebooting for unknown reasons -- it suffered from a phenomenon called priority inversion, where a low-priority thread kept blocking a high-priority one. We are going to explore this particular issue in more detail below. But this example should demonstrate that even with vast resources and lots of engineering talent available, concurrency can come back to bite you in many ways.
Sharing of Resources
The root of many concurrency related evils is the access of shared resources from multiple threads. A resource can be a property or an object, memory in general, a network device, a file, etc. Anything you share between multiple threads is a potential point of conflict, and you have to take safety measures to prevent these kind of conflicts.
In order to demonstrate the problem, let's look at a simple example of a resource in the form of an integer property which you're using as a counter. Let's say we have two threads running in parallel, A and B, and both try to increment the counter at the same time. The problem is that what you write as one statement in C or Objective-C is mostly not just one machine instruction for the CPU. To increment our counter, the current value has to be read from memory. Then the value is incremented by one and finally written back to memory.
Imagine the hazards that can happen if both threads try to do this simultaneously. For example, thread A and thread B both read the value of the counter from memory; let's say it is 17. Then thread A increments the counter by one and writes the resulting 18 back to memory. At the same time, thread B also increments the counter by one and writes a 18 back to memory, just after thread A. At this point the data has become corrupted, because the counter holds an 18 after it was incremented twice from a 17.
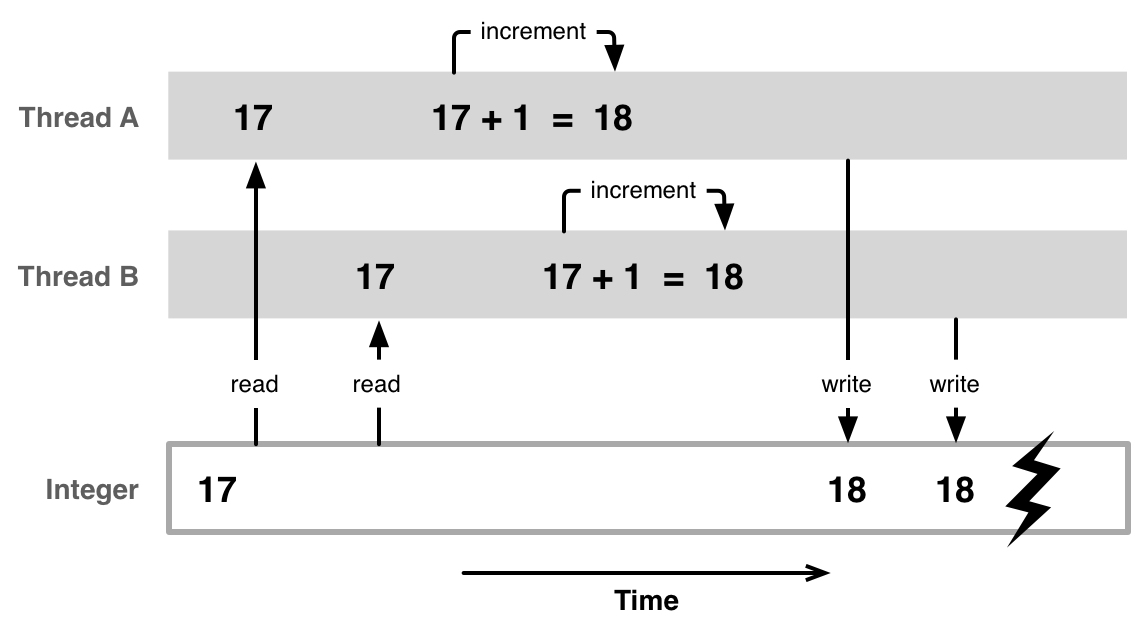
This problem is called a race condition and can always happen if multiple threads access a shared resource without making sure that one thread is finished operating on a resource before another one begins accessing it. If you're not only writing a simple integer but a more complex structure to memory, it might even happen that a second thread tries to read from this memory while you're in the midst of writing it, therefore seeing half new and half old or uninitialized data. In order to prevent this, multiple threads need to access shared resources in a mutually exclusive way.
In reality, the situation is even more complicated than this, because modern CPUs change the sequence of reads and writes to memory for optimization purposes (Out-of-order execution).
Mutual Exclusion
Mutual exclusive access means that only one thread at a time gets access to a certain resource. In order to ensure this, each thread that wants to access a resource first needs to acquire a mutex lock on it. Once it has finished its operation, it releases the lock, so that other threads get a chance to access it.
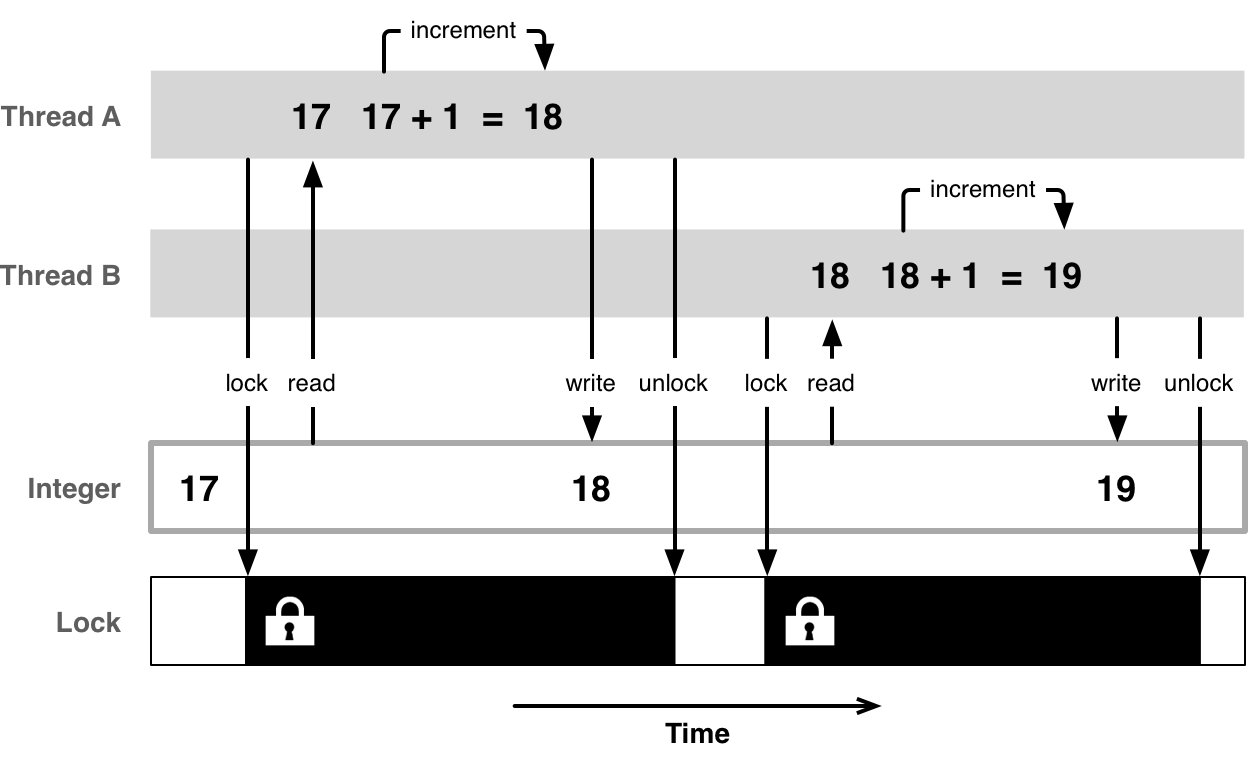
In addition to ensuring mutual exclusive access, locks must also handle the problem caused by out-of-order execution. If you cannot rely on the CPU accessing the memory in the sequence defined by your program instructions, guaranteeing mutually exclusive access alone is not enough. To work around this side effect of CPU optimization strategies, memory barriers are used. Setting a memory barrier makes sure that no out-of-order execution takes place across the barrier.
Of course the implementation of a mutex lock in itself needs to be race-condition free. This is a non-trivial undertaking and requires use of special instructions on modern CPUs. You can read more about atomic operations in Daniel's low-level concurrency techniques article.
Objective-C properties come with language level support for locking in the form of declaring them as atomic. In fact, properties are even atomic by default. Declaring a property as atomic results in implicit locking/unlocking around each access of this property. It might be tempting to just declare all properties as atomic, just in case. However, locking comes at a cost.
Acquiring a lock on a resource always comes with a performance cost. Acquiring and releasing a lock needs to be race-condition free, which is non-trivial on multi-core systems. And when acquiring a lock, the thread might have to wait because some other thread already holds the lock. In this case, that thread will sleep and has to be notified when the other thread relinquishes the lock. All of these operations are expensive and complicated.
There are different kinds of locks. Some locks are very cheap when there's no lock contention but perform poorly under contention. Other locks are more expensive at a base level, but degrade better under contention (Lock contention is the situation when one or more threads try to take a lock that has already been taken).
There is a trade-off to be made here: acquiring and releasing locks comes at a price (lock overhead). Therefore you want to make sure you're not constantly entering and exiting critical sections (i.e. acquiring and releasing locks). At the same time, if you acquire a lock for too large of a region of code, you run the risk of lock contention where other threads are often unable to do work because they're waiting to acquire a lock. It's not an easy task to solve.
It is quite common to see code which is supposed to run concurrently, but which actually results in only one thread being active at a time, because of the way locks for shared resources are set up. It's often non-trivial to predict how your code will get scheduled on multiple cores. You can use Instrument's CPU strategy view to get a better idea of whether you're efficiently using the available CPU cores or not.
Dead Locks
Mutex locks solve the problem of race conditions, but unfortunately they also introduce a new problem (amongst others) at the same time: dead locks. A dead lock occurs when multiple threads are waiting on each other to finish and get stuck.
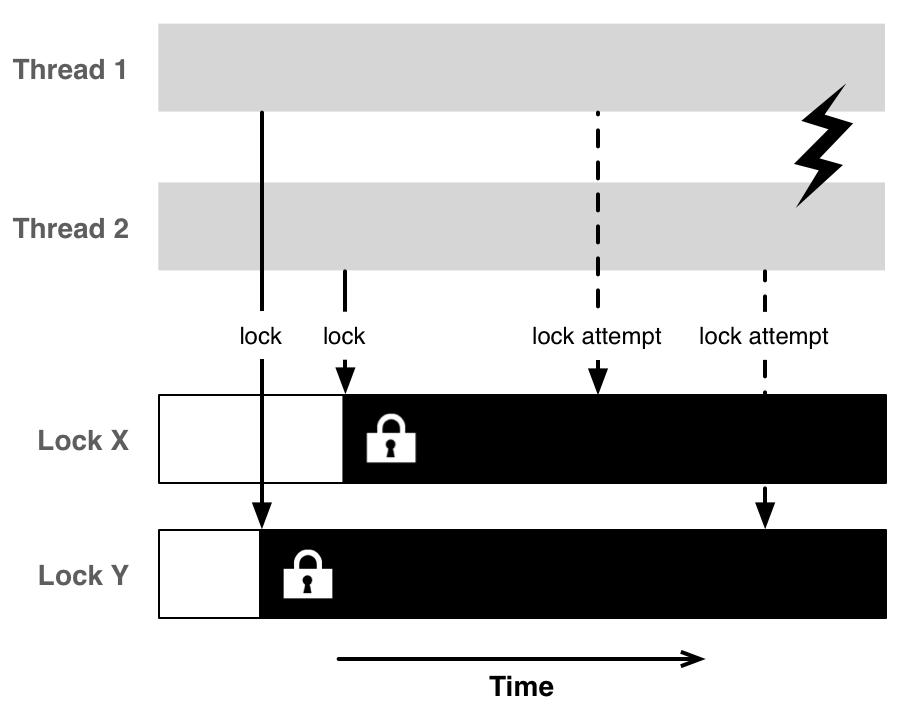
Consider the following example code, which swaps the values of two variables:
void swap(A, B)
{
lock(lockA);
lock(lockB);
int a = A;
int b = B;
A = b;
B = a;
unlock(lockB);
unlock(lockA);
}
This works quite well most of the time. But when by chance two threads call it at the same time with opposite variables
swap(X, Y); // thread 1
swap(Y, X); // thread 2
we can end up in a dead lock. Thread 1 acquires a lock on X, thread 2 acquires a lock on Y. Now they're both waiting for the other lock, but will never be able to acquire it.
Again, the more resources you share between threads and the more locks you take, the greater your risk of running into a dead lock situation. This is one more reason to keep things as simple as possible and to share as few resources as possible between threads. Make sure to also read the section about doing things asynchronously in the low-level concurrency APIs article.
Starvation
Just when you thought that there are enough problems to think of, a new one comes around the corner. Locking shared resources can result in the readers-writers problem. In many cases, it would be wasteful to restrict reading access to a resource to one access at a time. Therefore, taking a reading lock is allowed as long as there is no writing lock on the resource. In this situation, a thread that is waiting to acquire a write lock can be starved by more read locks occurring in the meantime.
In order to solve this issue, more clever solutions than a simple read/write lock are necessary, e.g. giving writers preference or using the read-copy-update algorithm. Daniel shows in his low-level concurrency techniques article how to implement a multiple reader/single writer pattern with GCD which doesn't suffer from writer starvation.
Priority Inversion
We started this section with the example of NASA's Pathfinder rover on Mars suffering from a concurrency problem. Now we will have a closer look why Pathfinder almost failed, and why your application can suffer from the same problem, called priority inversion.
Priority inversion describes a condition where a lower priority task blocks a higher priority task from executing, effectively inverting task priorities. Since GCD exposes background queues with different priorities, including one which even is I/O throttled, it's good to know about this possibility.
The problem can occur when you have a high-priority and a low-priority task share a common resource. When the low-priority task takes a lock to the common resource, it is supposed to finish off quickly in order to release its lock and to let the high-priority task execute without significant delays. Since the high-priority task is blocked from running as long as the low-priority task has the lock, there is a window of opportunity for medium-priority tasks to run and to preempt the low-priority task, because the medium-priority tasks have now the highest priority of all currently runnable tasks. At this moment, the medium-priority tasks hinder the low-priority task from releasing its lock, therefore effectively gaining priority over the still waiting, high-priority tasks.
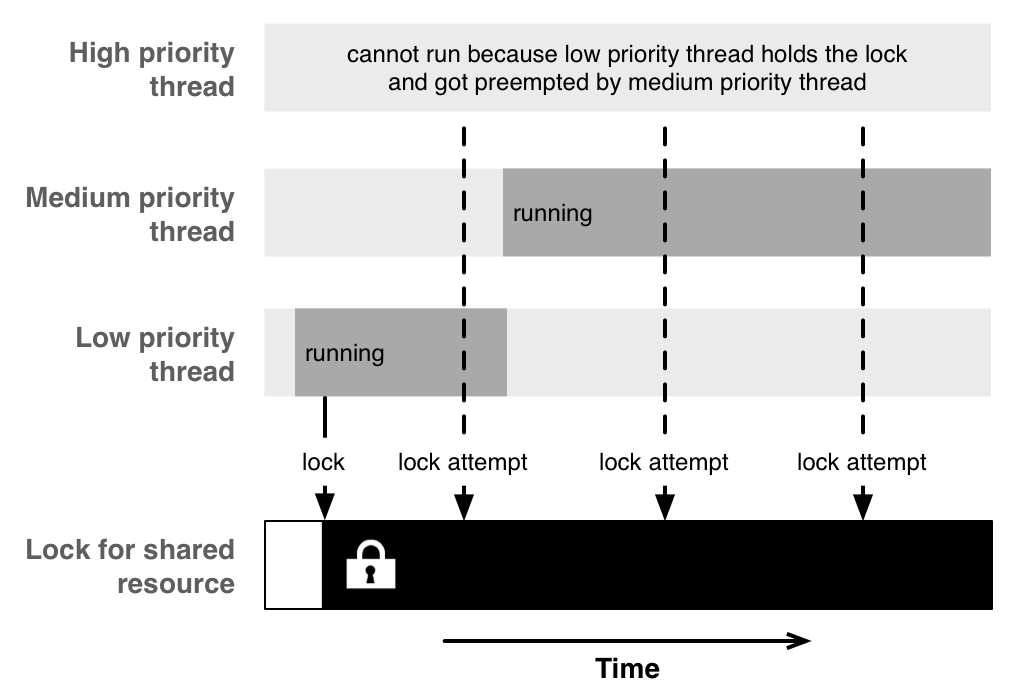
In your own code, things might not be as dramatic as the rebooting that occurred in the Mars rover, as priority inversion happens quite often in a less severe manner.
In general, don't use different priorities. Often you will end up with high-priority code waiting on low-priority code to finish. When you're using GCD, always use the default priority queue (directly, or as a target queue). If you're using different priorities, more likely than not, it's actually going to make things worse.
The lesson from this is that using multiple queues with different priorities sounds good on paper, but it adds even more complexity and unpredictability to concurrent programs. And if you ever run into a weird problem where your high-priority tasks seem to get stuck for no reason, maybe you will remember this article and the problem called priority inversion, which even the NASA engineers encountered.
Conclusion
We hope to have demonstrated the complexity of concurrent programming and its problems, no matter how straightforward an API may look. The resulting behavior quickly gets very difficult to oversee, and debugging these kind of problems is often very hard.
On the other hand, concurrency is a powerful tool to take advantage of the computing power of modern multicore CPUs. The key is to keep your concurrency model as simple as possible, so that you can limit the amount of locking necessary.
A safe pattern we recommend is this: pull out the data you want to work on the main thread, then use an operation queue to do the actual work in the background, and finally get back onto the main queue to deliver the result of your background work. This way, you don't need to do any locking yourself, which greatly reduces the chances for mistakes.