Core Data
Core Data best practices by example, from persistency to multithreading and syncing.
by Florian Kugler and Daniel Eggert
Introduction
Core Data is Apple’s object graph management and persistency framework for iOS, macOS, watchOS, and tvOS. If your app needs to persist structured data, Core Data is the obvious solution to look into: it’s already there, it’s actively maintained by Apple, and it has been around for more than 10 years. It’s a mature, battle-tested code base.
Nevertheless, Core Data can also be somewhat confusing at first; it’s flexible, but it’s not obvious how to best use its API. That said, the goal of this book is to help you get off to a flying start. We want to provide you with a set of best practices — ranging from simple to advanced use cases — so that you can take advantage of Core Data’s capabilities without getting lost in unnecessary complexities.
For example, Core Data is often blamed for being difficult to use in a multithreaded environment. But Core Data has a very clear and consistent concurrency model. Used correctly, it helps you avoid many of the pitfalls inherent to concurrent programming. The remaining complexities aren’t specific to Core Data but rather to concurrency itself. We go into those issues in the chapter about problems that can occur with multiple contexts, and in another chapter, we show a practical example of a background syncing solution.
Similarly, Core Data often has the reputation of being slow. If you try to use it like a relational database, you’ll find that it has a high performance overhead compared to, for example, using SQLite directly. However, when using Core Data correctly – treating it as an object graph management system – there are actually quite a few places where it ends up being faster due to its built-in caches and object management. Furthermore, the higher-level API lets you focus on optimizing the performance-critical parts of your application instead of reimplementing persistency from scratch. Throughout this book, we’ll also describe best practices to keep Core Data performant. We’ll take a look at how to approach performance issues in the dedicated chapter about performance, as well as in the profiling chapter.
How This Book Approaches Core Data
This book shows how to use Core Data with working examples — it’s not an extended API manual. We deliberately focus on best practices within the context of complete examples. We do so because, in our experience, stringing all the parts of Core Data together correctly is where most challenges occur.
In addition, this book provides an in-depth explanation of Core Data’s inner workings. Understanding this flexible framework helps you make the right decisions and, at the same time, keep your code simple and approachable. This is particularly true when it comes to concurrency and performance.
Sample Code
You can get the complete source code for an example app on GitHub. We’re using this app in many parts of the book to show problems and solutions in the context of a larger project. We’ve included the sample project in several stages so that the code on GitHub matches up with the code snippets in the book as best as possible.
Structure
In the first part of the book, we’ll start building a simple version of our app to demonstrate the basic principles of how Core Data works and how you should use it. Even if the early examples sound trivial to you, we still recommend you go over these sections of the book, as the later, more complex examples build on top of the best practices and techniques introduced early on. Furthermore, we want to show you that Core Data can be extremely useful for simple use cases as well.
The second part focuses on an in-depth understanding of how all the parts of Core Data play together. We’ll look in detail at what happens when you access data in various ways, as well as what occurs when you insert or manipulate data. We cover much more than what’s necessary to write a simple Core Data application, but this knowledge can come in handy once you’re dealing with larger or more complex setups. Building on this foundation, we conclude this part with a chapter about performance considerations.
The third part starts with describing a general purpose syncing architecture to keep your local data up to date with a network service. Then we go into the details of how you can use Core Data with multiple managed object contexts at once. We present different options to set up the Core Data stack and discuss their advantages and disadvantages. The last chapter in this part describes how to navigate the additional complexity of working with multiple contexts concurrently.
The fourth part deals with advanced topics like advanced predicates, searching and sorting text, how to migrate your data between different model versions, and tools and techniques to profile the performance of your Core Data stack. It also includes a chapter that introduces the basics of relational databases and the SQL query language from the perspective of Core Data. If you’re not familiar with these, it can be helpful to go through this crash course, especially to understand potential performance issues and the profiling techniques required to tackle them.
A Note on Swift
Throughout this book, we use Swift for all examples. We embrace Swift’s language features — like generics, protocols, and extensions — to make working with Core Data’s API elegant, easier, and safer.
However, all the best practices and patterns we show in Swift can be applied in an Objective-C code base as well. The implementation will be a bit different in some aspects, in order to fit the language, but the underlying principles remain the same.
Conventions for Optionals
Swift provides the Optional data type, which enables and forces us to explicitly think about and handle cases of missing values. We’re big fans of this feature, and we use it consistently throughout all examples.
Consequently, we avoid using Swift’s ! operator to force-unwrap optionals (along with its usage to define implicitly unwrapped types). We consider this a code smell, since it undermines the safety that comes from having an optional type in the first place.
That being said, the single exception to this rule is properties that have to be set but can’t be set at initialization time. Examples of this are Interface Builder outlets or required delegate properties. In these cases, using implicitly unwrapped optionals follows the “crash early” rule: we want to notice immediately when one of these required properties hasn’t been set.
Conventions for Error Handling
There are a few methods in Core Data that can throw errors. Our rationale for how we handle errors is based on the fact that there are different kinds of errors. We’ll differentiate between errors due to logic failures and all other errors.
Logic errors are the result of the programmer making a mistake. They should be handled by fixing the code and not by trying to recover dynamically.
An example is when code tries to read a file that’s part of the app bundle. Since the app bundle is read-only, a file either exists or doesn’t, and its content will never change. If we fail to open or parse a file in the app bundle, that’s a logic error.
For these kinds of errors, we use Swift’s try! or fatalError() in order to crash as early as possible.
The same line of thought goes for casting with as!: if we know that an object must be of a certain type, and the only reason it could fail would be due to a logic error, we actually want the app to crash.
Quite often we’ll use Swift’s guard keyword to be more expressive about what went wrong. For example, if we know that a managed object’s managedObjectContext property has to be non-nil, we’ll use a guard let statement with an explicit fatalError in the else branch. This makes the intention clearer compared to just force unwrapping it.
For recoverable errors that aren’t logic errors, we use Swift’s error propagation method: throwing or re-throwing errors.
Hello Core Data
In this chapter, we’re going to build a simple app that uses Core Data. In the process, we’ll explain the basic architecture of Core Data and how to use it correctly for this scenario. Naturally, there’s more to say about almost every aspect we touch on in this chapter, but rest assured we’ll revisit all these topics in more detail later on.
This chapter covers all the Core Data-related aspects of the example app; it’s not meant to be a step-by-step tutorial to build the whole app from scratch. We recommend that you look at the full code on GitHub to see all the different parts in context.
The example app consists of one simple screen with a table view and a live camera feed at the bottom. After snapping a picture, we extract an array of dominant colors from it, store this color scheme (we call it a “mood”), and update the table view accordingly:
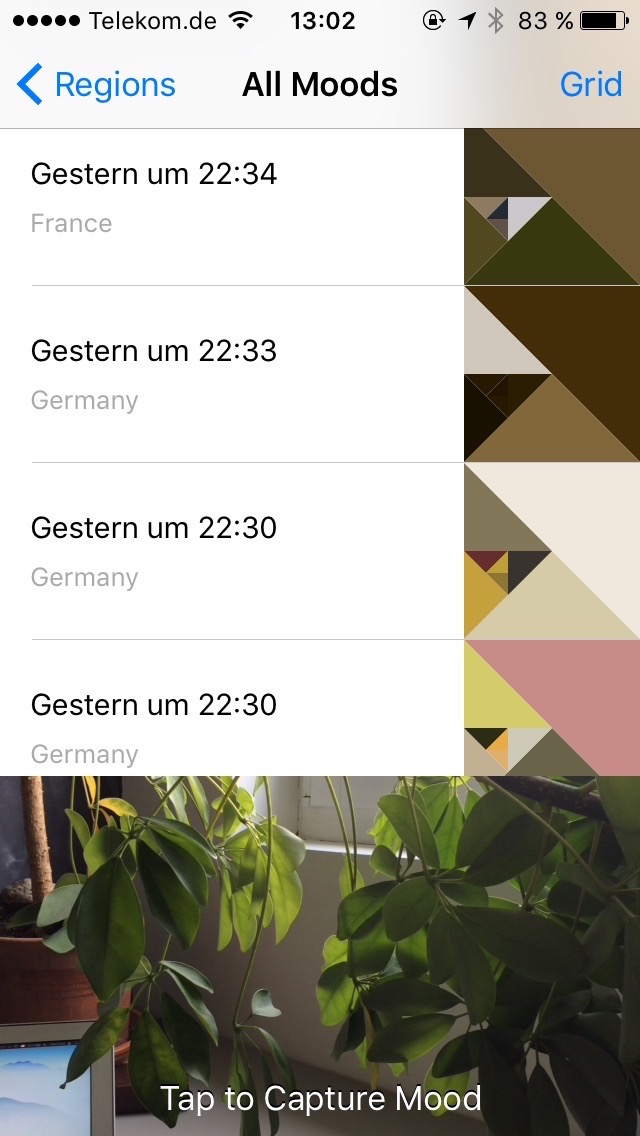
The sample app “Moody”
Core Data Architecture
Before we start building the example app, we’ll first take a look at the major building blocks of Core Data to get a better understanding of its architecture. We’ll come back to the details of how all the pieces play together in part two.
A basic Core Data stack consists of four major parts: the managed objects (NSManagedObject), the managed object context (NSManagedObjectContext), the persistent store coordinator (NSPersistentStoreCoordinator), and the persistent store (NSPersistentStore):
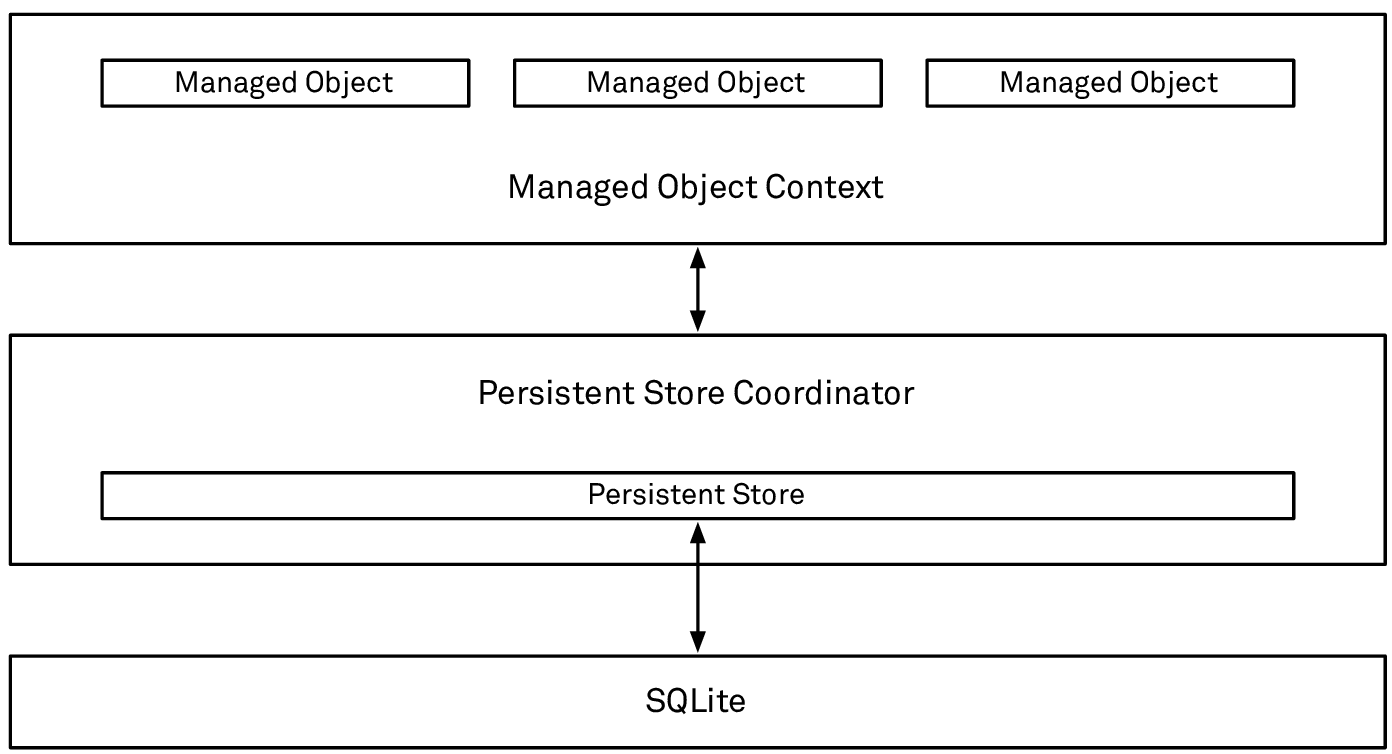
The components of a basic Core Data stack
The managed objects at the top of this graph are the most interesting part and will be our model objects — in this case, instances of the Mood class. Mood needs to be a subclass of NSManagedObject — that’s how it integrates with the rest of Core Data. Each Mood instance represents one of the moods, i.e. snapshots the user takes with the camera.
Our mood objects are managed objects. They’re managed by Core Data, which means they live in a specific context: a managed object context. The managed object context keeps track of its managed objects and all the changes you make to them, i.e. insertions, deletions, and updates. And each managed object knows which context it belongs to. Core Data supports multiple contexts, but let’s not get ahead of ourselves: for most simple setups, like the one in this chapter, we’ll only use one context.
The context connects to a persistent store coordinator. It sits between the persistent store and the managed object context and takes a coordinating role between the two. For the simple example in this chapter, we don’t have to worry about the persistent store coordinator or the persistent store, since the NSPersistentContainer helper class will set all this up for us. Suffice it to say that, by default, a persistent store of the SQLite flavor is used, i.e. your data will be stored in an SQLite database under the hood. Core Data provides other store types (XML, binary, in-memory), but we don’t need to worry about them at this point.
We’ll revisit all the parts of the Core Data stack in detail in the chapter about accessing data in part two.
Data Modeling
Core Data stores structured data. In order to use Core Data, we first have to create a data model (a schema, if you will) that describes the structure of our data.
You can define a data model in code. It’s easier, however, to use Xcode’s model editor to create and edit an .xcdatamodeld bundle. When you start with an empty Xcode template for an iOS or macOS app, you create a data model by going to File > New and choosing “Data Model” from the Core Data section. If you clicked the “Use Core Data” checkbox when first creating the project, an empty data model has already been created for you.
However, you don’t need to click the “Use Core Data” checkbox to use Core Data in your project — on the contrary, we suggest you don’t, since we’ll throw out all the generated boilerplate code anyway.
Once you select the data model in the project navigator, Xcode’s data model editor opens up, and we can start to work on our model.
Entities and Attributes
Entities are the building blocks of the data model. As such, an entity should represent a piece of data that’s meaningful to your application. For example, in our case, we create an entity called Mood, which has two attributes: one for the colors, and one for the date of the snapshot. By convention, entity names start with an uppercase letter, analogous to class names.
Core Data supports a number of different data types out of the box: numeric types (integers and floating-point values of different sizes, as well as decimal numbers), strings, booleans, dates, and binary data, as well as the transformable type that stores any object conforming to NSCoding or objects for which you provide a custom value transformer.
For the Mood entity, we create two attributes: one of type Date (named date), and one of type Transformable (named colors). Attribute names should start with a lowercase letter, just like properties in a class or a struct. The colors attribute holds an array of UIColor objects. Since NSArray and UIColor are already NSCoding compliant, we can store such an array directly in a transformable attribute:
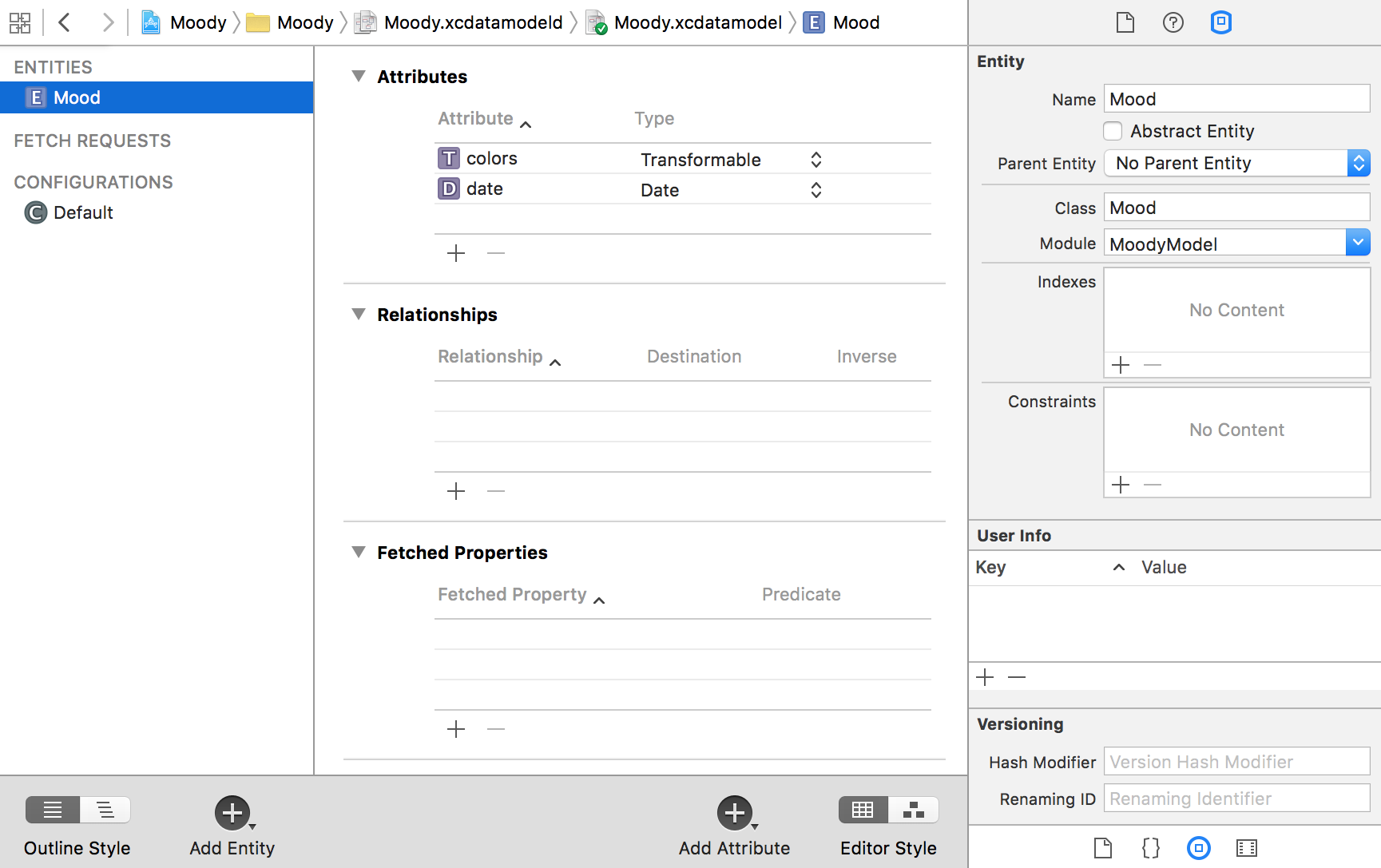
The Mood entity in Xcode’s model editor
Attribute Options
Both attributes have a few more options we need to adjust. We mark the date attribute as non-optional and indexed and the color sequence attribute as non-optional.
Non-optional attributes have to have a valid value assigned to them in order to be able to save the data. Marking an attribute as indexed creates an index on the underlying SQLite database table. An index speeds up finding and sorting records by this attribute — at the cost of reduced performance when inserting new records and some additional storage space. In our case, we’ll display the mood objects sorted by date, so it makes sense to index this attribute. We go into more depth on the topic of indexes in the chapters about performance and profiling:
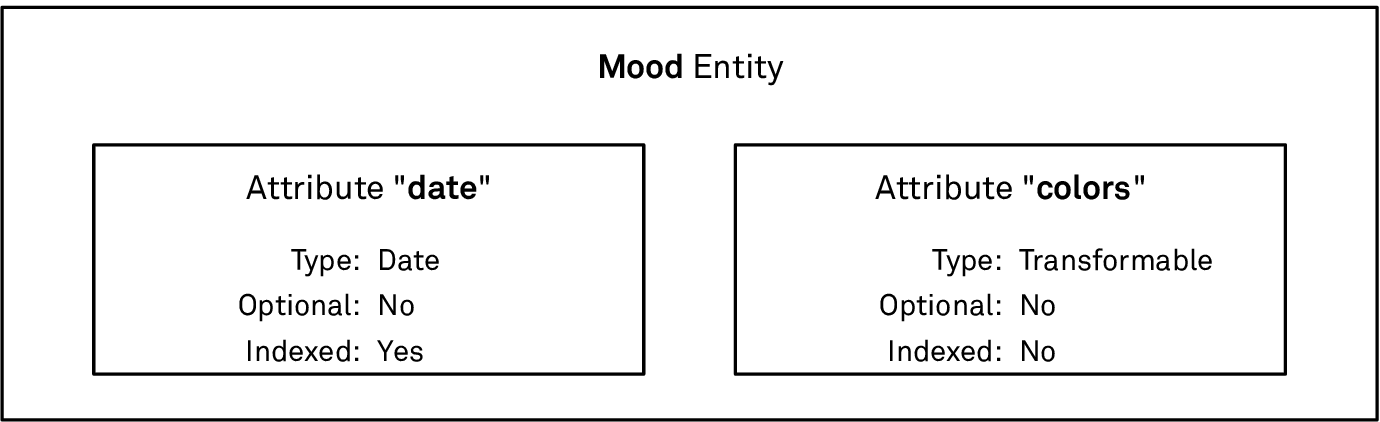
The attributes of the Mood entity
Managed Object Subclasses
Now that we’ve created the data model, we have to create a managed object subclass that represents the Mood entity. The entity is just a description of the data that belongs to each mood. In order to work with this data in our code, we need a class that has the properties corresponding to the attributes we defined on the entity.
It’s good practice to name those classes by what they represent, without adding suffixes like Entity to them. Our class will simply be called Mood and not MoodEntity. Both the entity and the class will be called Mood, and that’s perfectly fine.
For creating the class, we advise against using Xcode’s code generation tool (Editor > Create NSManagedObject Subclass...) and instead suggest simply writing it by hand. In the end, it’s just a few lines of code you have to type once, and there’s the upside of being fully in control of how you write it. Additionally, it makes the process more transparent — you’ll see that there’s no magic involved.
Our Mood entity looks like this in code:
final class Mood: NSManagedObject {
@NSManaged fileprivate(set) var date: Date
@NSManaged fileprivate(set) var colors: [UIColor]
}
The @NSManaged attributes on the properties in the Mood class tell the compiler that those properties are backed by Core Data attributes. Core Data implements them in a very different way, but we’ll talk about this in more detail in part two. The fileprivate(set) access control modifiers specify that both properties are publicly readable, but not writable. Core Data doesn’t enforce such a read-only policy, but with those annotations in our class definition, the compiler will.
In our case, there’s no need to expose the aforementioned attributes to the world as writable. We’ll create a helper method later on to insert new moods with specific values upon creation, and we never want to change these values after that. In general, it’s best to only publicly expose those properties and methods of your model objects that you really need to expose.
To make Core Data aware of our Mood class, and to associate it with the Mood entity, we select the entity in the model editor and type the class name in the data model inspector.
Setting Up the Stack
Now that we have the first version of our data model and the Mood class in place, we can set up a basic Core Data stack using NSPersistentContainer. We’ll use the following function to create the container, from which we can get the managed object context we’re going to use throughout the app:
func createMoodyContainer(completion: @escaping (NSPersistentContainer) -> ()) {
let container = NSPersistentContainer(name: "Moody")
container.loadPersistentStores { _, error in
guard error == nil else { fatalError("Failed to load store: \(error!)") }
DispatchQueue.main.async { completion(container) }
}
}
Let’s go through this step by step.
First, we create a persistent container with a name. Core Data uses this name to look up the data model, so it should match the file name of your .xcdatamodeld bundle. Next, we call loadPersistentStores on the container, which tries to open the underlying database file. If the database doesn’t exist yet, Core Data will generate it with the schema you defined in the data model.
Since loading the persistent stores (in our case – as in most real-world use cases – it’s just one store) takes place asynchronously, we get a callback once a store has been loaded. If an error occurred, we simply crash for now. In production, you might want to react differently, e.g. by migrating an existing store to a newer version or by deleting and recreating the store as a measure of last resort.
Finally, we dispatch back onto the main queue and call the completion handler of our createMoodyContainer function with the new persistent container.
Since we’ve encapsulated this boilerplate code in a neat helper function, we can initialize the persistent container from the application delegate with a single call to createMoodyContainer:
class AppDelegate: UIResponder, UIApplicationDelegate {
var persistentContainer: NSPersistentContainer!
var window: UIWindow?
func application(_ application: UIApplication, didFinishLaunchingWithOptions launchOptions: [UIApplicationLaunchOptionsKey: Any]?) -> Bool {
createMoodyContainer { container in
self.persistentContainer = container
let storyboard = self.window?.rootViewController?.storyboard
guard let vc = storyboard?.instantiateViewController(withIdentifier: "RootViewController") as? RootViewController
else { fatalError("Cannot instantiate root view controller") }
vc.managedObjectContext = container.viewContext
self.window?.rootViewController = vc
}
return true
}
}
Once we get the callback with the persistent container, we store it in a property. Then we swap out the initial view controller loaded at application launch (which is just a placeholder until we’re done loading the store) with our app’s root view controller. We instantiate the root view controller from the storyboard, set the managed object context on it, and install it as the window’s root view controller.
Showing the Data
Now that we’ve initialized the Core Data stack, we can use the managed object context we created in the application delegate to query for data we want to display.
In order to use the managed object context in the view controllers of our app, we hand the context object from the application delegate to the first view controller, and later, from there to other view controllers in the hierarchy that need access to the context. For example, in prepareForSegue, the root view controller passes the context on to the MoodTableViewController:
override func prepare(for segue: UIStoryboardSegue, sender: Any?) {
switch segueIdentifier(for: segue) {
case .embedNavigation:
guard let nc = segue.destination as? UINavigationController,
let vc = nc.viewControllers.first as? MoodsTableViewController
else { fatalError("wrong view controller type") }
vc.managedObjectContext = managedObjectContext
// ...
}
}
// ...
The pattern is very similar to what we did in the application delegate, but now we first have to go through the navigation controller to get to the MoodsTableViewController instance.
In case you were wondering where the segueIdentifier(for:) comes from, we took this pattern from the Swift in Practice session, presented at WWDC 2015. It’s a nice use case of protocol extensions in Swift, which makes segues more explicit and lets the compiler check if we’ve handled all cases.
To display the mood objects — we don’t have any yet, but we’ll take care of that in a bit — we use a table view in combination with Core Data’s NSFetchedResultsController. This controller class watches out for changes in our dataset and informs us about those changes in a way that makes it very easy to update the table view accordingly.
Fetch Requests
As the name indicates, a fetch request describes what data is to be fetched from the persistent store and how. We’ll use it to retrieve all Mood instances, sorted by their creation dates. Fetch requests also allow very complex filtering in order to only retrieve specific objects. In fact, fetch requests are so powerful that we’ll save most of the details of what they can do for later.
One important thing we want to point out now is this: every time you execute a fetch request, Core Data goes through the complete Core Data stack, all the way to the file system. By contract, a fetch request is a round trip: from the context, through the persistent store coordinator and the persistent store, down to SQLite, and then all the way back.
While fetch requests are very powerful workhorses, they incur a lot of work. Executing a fetch request is a comparatively expensive operation. We’ll go into more detail in part two about why this is and how to avoid these costs, but for now, we just want you to remember you should use fetch requests thoughtfully, and that they’re a point of potential performance bottlenecks. Often, they can be avoided by traversing relationships, something which we’ll also cover later.
Let’s turn back to our example. Here’s how we could create a fetch request to retrieve all Mood instances from Core Data, sorted by their creation dates in a descending order (we’ll clean this code up shortly):
let request = NSFetchRequest<Mood>(entityName: "Mood")
let sortDescriptor = NSSortDescriptor(key: "date", ascending: false)
request.sortDescriptors = [sortDescriptor]
request.fetchBatchSize = 20
The entityName is the name our Mood entity has in the data model. The fetchBatchSize property tells Core Data to only fetch a certain number of mood objects at a time. There’s a lot of magic going on behind the scenes for this to work; we’ll dive into the mechanics of it all in the chapter about accessing data. We’re using 20 as the fetch batch size, because that roughly corresponds to twice the number of items on screen at the same time. We’ll come back to adjusting the batch size in the performance chapter.
Simplified Model Classes
Before we go ahead and use this fetch request, we’ll take a step back and add a few things to our model class to keep our code easy to use and maintain.
We want to demonstrate a way to create fetch requests that better separates concerns. This pattern will also come in handy later for many other aspects of the example app as we expand it.
Protocols play a central role in Swift. We’ll add a protocol that our Mood model class will implement. In fact, all model classes we add later will implement this too — and so should yours:
protocol Managed: class, NSFetchRequestResult {
static var entityName: String { get }
static var defaultSortDescriptors: [NSSortDescriptor] { get }
}
We’ll make use of Swift’s protocol extensions to add a default implementation for defaultSortDescriptors as well as a computed property to get a fetch request with the default sort descriptors for this entity:
extension Managed {
static var defaultSortDescriptors: [NSSortDescriptor] {
return []
}
static var sortedFetchRequest: NSFetchRequest<Self> {
let request = NSFetchRequest<Self>(entityName: entityName)
request.sortDescriptors = defaultSortDescriptors
return request
}
}
Furthermore, we’ll add a default implementation for the static entityName property by using a protocol extension that’s constrained to NSManagedObject subtypes:
extension Managed where Self: NSManagedObject {
static var entityName: String { return entity().name! }
}
Now we make the Mood class conform to Managed and provide a specific implementation for defaultSortDescriptors: we want the Mood instances to be sorted by date by default (just like the fetch request we created before):
extension Mood: Managed {
static var defaultSortDescriptors: [NSSortDescriptor] {
return [NSSortDescriptor(key: #keyPath(date), ascending: false)]
}
}
With this extension, we can create the same fetch request as above, like this:
let request = Mood.sortedFetchRequest
request.fetchBatchSize = 20
We’ll later build upon this pattern and add more convenience methods to the Managed protocol — for example, when creating fetch requests with specific predicates or finding objects of this type. You can check out all the extensions on Managed in the sample code.
At this point, it might seem like unnecessary overhead for what we’ve gained. It’s a much cleaner design, though, and a better foundation to build upon. As our app grows, we’ll make more use of this pattern.
Fetched Results Controller
We use the NSFetchedResultsController class to mediate between the model and view. In our case, we use it to keep the table view up to date with the mood objects in Core Data, but fetched results controllers can also be used in other scenarios — for example, with a collection view.
The main advantage of using a fetched results controller — instead of simply executing a fetch request ourselves and handing the results to the table view — is that it informs us about changes in the underlying data in a way that makes it easy to update the table view. To achieve this, the fetched results controller listens to a notification, which gets posted by the managed object context whenever the data in the context changes (more on this in the chapter about changing and saving data). Respecting the sorting of the underlying fetch request, it figures out which objects have changed their positions, which have been newly inserted, etc., and reports those changes to its delegate:
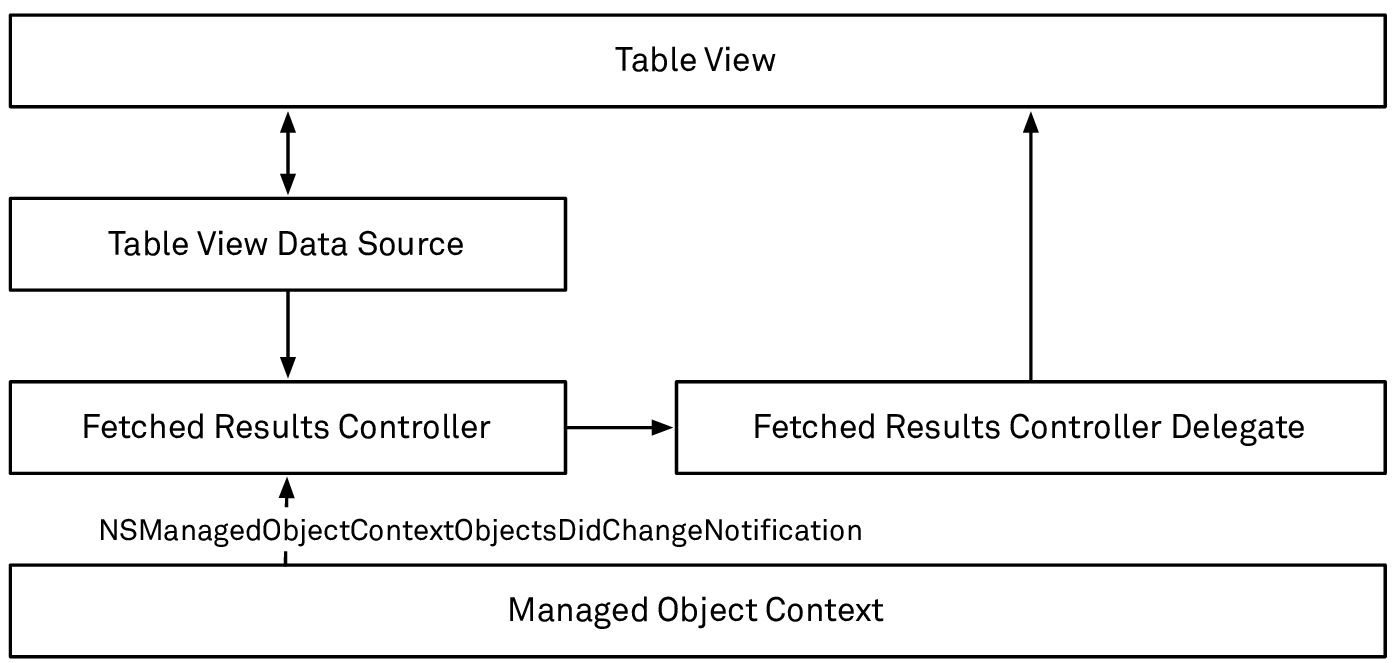
How the fetched results controller interacts with the table view
To initialize the fetched results controller for the mood table view, we call setupTableView from viewDidLoad in the UITableViewController subclass. setupTableView uses the fetch request above to create a fetched results controller:
fileprivate func setupTableView() {
// ...
let request = Mood.sortedFetchRequest
request.fetchBatchSize = 20
request.returnsObjectsAsFaults = false
let frc = NSFetchedResultsController(fetchRequest: request, managedObjectContext: managedObjectContext, sectionNameKeyPath: nil, cacheName: nil)
// ...
}
The delegate of a fetched results controller has to implement the following three methods, which inform us about changes in the underlying data (technically, you could get away with only implementing the last one, but that would defy the purpose of using a fetched results controller):
controllerWillChangeContent(_:)controller(_:didChange:at:for:newIndexPath:)controllerDidChangeContent(_:)
We could simply implement the above methods in the view controller class. However, this would clutter up the view controller with a lot of boilerplate code. Furthermore, we’d have to repeat all this boilerplate code in each view controller that should use a fetched results controller. Therefore, we’re going to do this correct from the start and encapsulate the fetched results controller’s delegate methods in a reusable class that serves as a table view’s data source at the same time. We initialize an instance of this in the view controller’s setupTableView method:
fileprivate func setupTableView() {
// ...
dataSource = TableViewDataSource(tableView: tableView, cellIdentifier: "MoodCell", fetchedResultsController: frc, delegate: self)
}
During initialization, the TableViewDataSource sets itself as the fetched results controller’s delegate as well as the table view’s data source. Then it calls performFetch to load the data from the persistent store. Since this call can throw an error, we prefix it with try! to crash early, since this would indicate a programming error:
class TableViewDataSource<Delegate: TableViewDataSourceDelegate>: NSObject, UITableViewDataSource, NSFetchedResultsControllerDelegate {
typealias Object = Delegate.Object
typealias Cell = Delegate.Cell
required init(tableView: UITableView, cellIdentifier: String, fetchedResultsController: NSFetchedResultsController<Object>, delegate: Delegate) {
self.tableView = tableView
self.cellIdentifier = cellIdentifier
self.fetchedResultsController = fetchedResultsController
self.delegate = delegate
super.init()
fetchedResultsController.delegate = self
try! fetchedResultsController.performFetch()
tableView.dataSource = self
tableView.reloadData()
}
// ...
}
The NSFetchedResultsControllerDelegate methods only contain standard boilerplate code to interface with the table view. Please check the sample project for the full source code of this class.
With the fetched results controller and its delegate in place, we can now move on to actually showing the data in the table view. For this, we implement the two essential table view data source methods in our custom TableViewDataSource class. Within those methods, we use the fetched results controller to retrieve the necessary data:
func tableView(_ tableView: UITableView, numberOfRowsInSection section: Int) -> Int {
guard let section = fetchedResultsController.sections?[section] else { return 0 }
return section.numberOfObjects
}
func tableView(_ tableView: UITableView, cellForRowAt indexPath: IndexPath) -> UITableViewCell {
let object = fetchedResultsController.object(at: indexPath)
guard let cell = tableView.dequeueReusableCell(withIdentifier: cellIdentifier, for: indexPath) as? Cell
else { fatalError("Unexpected cell type at \(indexPath)") }
delegate.configure(cell, for: object)
return cell
}
Within the tableView(_:cellForRowAt:) method, we ask the delegate of the TableViewDataSource to configure a specific cell. This way, we can reuse the TableViewDataSource class for other table views in the app, since it doesn’t contain any code specific to the table view of moods. The moods view controller implements this delegate method by passing on the Mood instance to a configure method on the cell:
extension MoodsTableViewController: TableViewDataSourceDelegate {
func configure(_ cell: MoodTableViewCell, for object: Mood) {
cell.configure(for: object)
}
}
You can check out the details of the table view cell code on GitHub.
We’ve come pretty far already. We’ve created the model, set up the Core Data stack, handed the managed object context through the view controller hierarchy, created a fetch request, and hooked up a table view via a fetched results controller in order to display the data. The only thing missing at this point is actual data that we can display, so let’s move on to that.
Relationships
In this chapter, we’ll expand our data model by adding two new entities: Country and Continent. During this process, we’ll explain the concept of subentities and when you should and shouldn’t use them. Then we’ll establish relationships between our three entities. Relationships are a key feature of Core Data, and we’ll use them to associate each mood with a country, and each country with a continent.
You can have look at the full source code of the sample project as we use it in this chapter on GitHub.
Data Types
In this chapter, we’ll take a more detailed look at the data types Core Data supports out of the box. We’ll also address how to store custom data types in different ways involving tradeoffs between convenience, data size, and performance.
Accessing Data
In this chapter, we’ll dive into the details of how all the parts of Core Data play together when you access persisted data in various ways. We’ll also take a look at the advanced options Core Data exposes to gain more control over the whole process. Later on, we’ll discuss one of the major reasons for all this machinery under the hood: memory efficiency and performance. Core Data does a lot of heavy lifting in order for you to be able to work with huge datasets.
You don’t need to know all this to use Core Data in straightforward scenarios. However, it can be helpful to have an understanding of what’s happening behind the scenes once you’re dealing with more complex setups or large-scale setups with thousands of objects.
Throughout this chapter, we’ll assume that we’re working with the default SQLite persistent store.
Fetch Requests
Fetch requests are the most obvious way to get objects from Core Data. Let’s take a look at what happens when you execute a very simple fetch request without touching any of its configuration options:
let request = NSFetchRequest<Mood>(entityName: "Mood")
let moods = try! context.fetch(request)
Let’s go through this step by step:
The context forwards the fetch request to its persistent store coordinator by calling
execute(_ request :with context:). Note how the context passes itself on as the second argument — this will be used later on.The persistent store coordinator forwards the request to all of its persistent stores (in case you have multiple) by calling each store’s
execute(_ request:with context:)method. Again: the context from which the fetch request originated is passed to the store.The persistent store converts the fetch request into an SQL statement and sends this query to SQLite.
SQLite executes the query on the data in the store’s database file(s) and returns all rows matching this query to the store (cf. the chapter about SQLite for more on this). The rows contain both the object IDs and the raw data (since the fetch request’s
includesPropertyValuesoption istrueby default). Object IDs uniquely identify records in the store — in fact, they’re a combination of the store’s ID, the table’s ID, and the row’s primary key in the table.The raw data that’s returned is comprised of simple data types: numbers, strings, and binary blobs. It’s stored in the persistent store’s row cache associated with the object IDs and with a timestamp of when the cache entry was last updated. A row cache entry with a certain object ID lives as long as a managed object with this object ID exists, whether it’s a fault or not.
The persistent store instantiates managed objects for the object IDs it received from the SQLite store and returns them to the coordinator. It’s crucial for the store to be able to call
object(with:)on the originating context for this, because managed objects are tied to one specific context.The default behavior of fetch requests is to return managed objects (there are other result types, but we’ll set them aside for a bit). Those objects are faults by default, i.e. they’re lightweight objects that aren’t populated with the actual data yet. They’re promises to get the data once you need it (more on faulting below).
However, if an object with the same object ID already exists in the context, then this existing object will be used unchanged. This is called uniquing: Core Data guarantees that within a managed object context, there’s only a single object representing a certain piece of data, no matter how you get to it. Put differently: objects representing the same data within the same managed object context will compare equal using pointer equality.
The persistent store coordinator returns to the context the array of managed objects it got from the persistent store.
Before returning the results of the fetch request, the context considers its pending changes and updates the results accordingly, since the
includesPendingChangesflag on the fetch request istrueby default. (Pending changes are any updates, inserts, and deletions you’ve made within the managed object context that haven’t yet been saved.) Additional objects may be added to the result, or objects may be removed because they no longer match.Finally, an array with managed objects matching the fetch request is returned to the caller.
All of this happens synchronously, and the managed object context is blocked until the fetch request is finished. Prior to iOS 10/macOS 10.12, the persistent store coordinator was blocked as well.
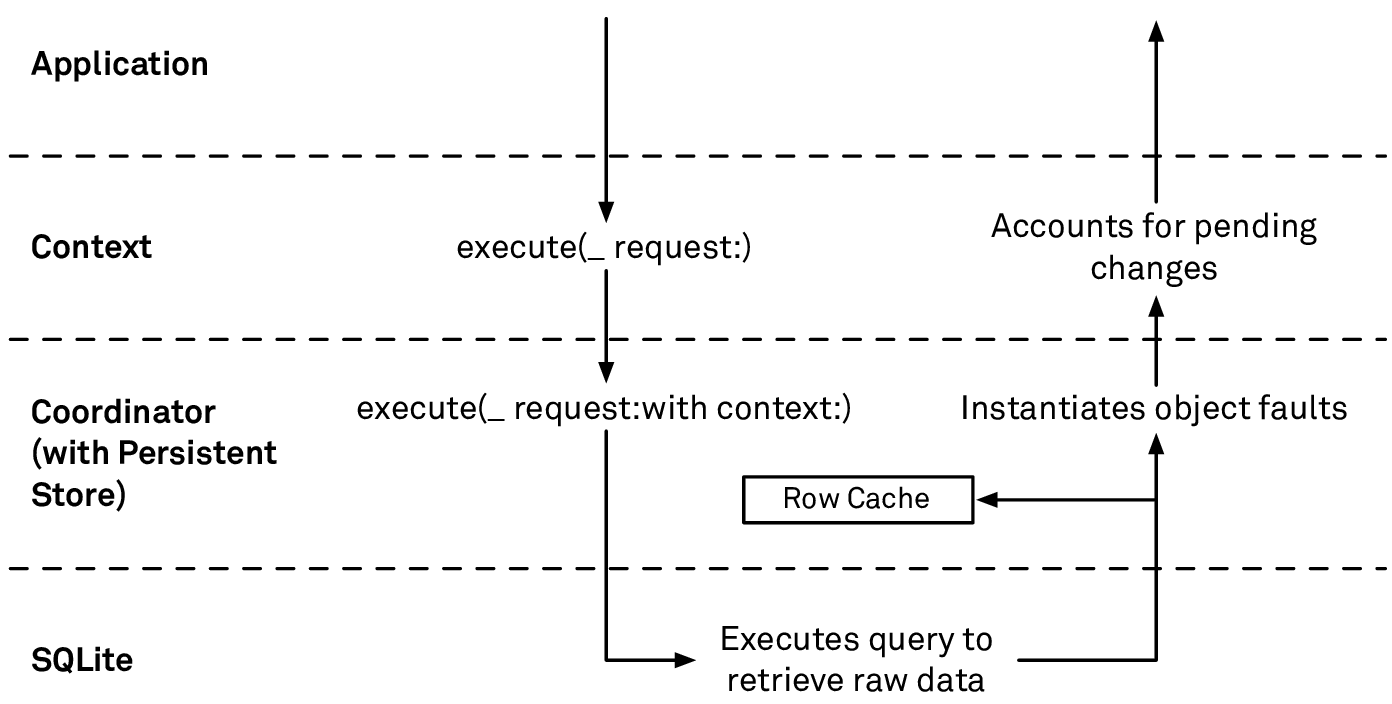
A fetch request makes a round trip all the way down to the SQLite store
At this point, you have an array of managed objects representing the data you asked for in the fetch request. However, since these objects are faults, a few more things have to happen to actually access the data of these objects. We’ll look at them in the next section.
The most important parts in this process are Core Data’s faulting and uniquing mechanisms. Faulting allows you to work with large datasets without materializing all objects in memory. Uniquing makes sure you always get the same object for the same piece of data, and that there’s only a single copy of this object.
Changing and Saving Data
In this chapter, we’ll take an in-depth look at what happens in the Core Data stack when you make changes to the data — from change tracking over conflict detection to persisting the data. Furthermore, we’ll look at the more advanced APIs for making changes to many objects at once and explore how they work and what you have to do to use them successfully.
As in the previous chapter, we’ll assume that we’re working with the default SQLite persistent store.
Performance
In the previous chapters, we talked a lot about how Core Data works internally. In this chapter, we’ll look at the performance aspects of these internals, as well as how to put this knowledge to use in order to get excellent performance with Core Data.
It’s important to note that performance is more than just speed. Tuning your performance makes sure that your app is fast, animations are smooth, and the user doesn’t have to wait. But performance is also about energy usage: when you tune your app’s performance, you improve battery life. Both energy consumption and speed are affected by the same optimizations. Making sure your app runs well on a slow device will equally benefit users with new and fast devices, as the battery life will be better on those too.
Performance Characteristics of the Core Data Stack
One of the main performance gains comes from understanding the performance characteristics of the Core Data stack and putting them to use:
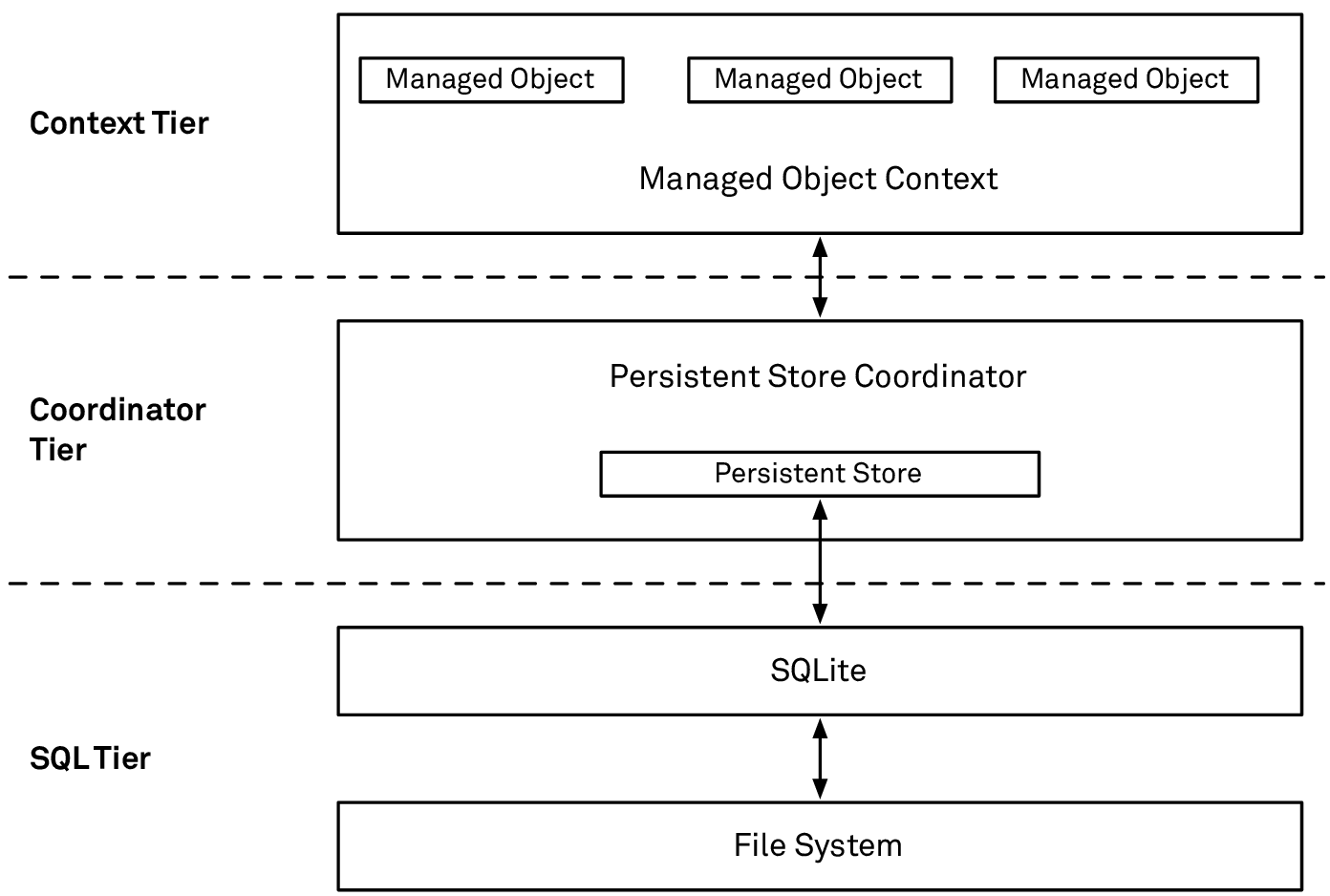
The different tiers in the Core Data stack have different performance characteristics
We can roughly divide the Core Data stack into three tiers. As we go down the stack, each tier is exponentially more complex — its performance impact is dramatically higher. This is a bold simplification, but it’s an extremely powerful mental model to help understand Core Data’s performance profile.
At the top of the stack are the managed objects and their context. Whenever we can keep operations inside this tier, performance will be extremely fast. The next tier is the persistent store coordinator with its row cache. And finally, there’s the SQL layer and the file system.
The tricky part is that our code will only ever use the top tier, but some operations will indirectly require Core Data to go down to the other tiers.
Syncing with a Network Service
Many apps sync their local data with a backend, and we want to illustrate an approach that works well as a generic setup for these scenarios. One of the key design goals of our syncing architecture is to ensure a clear separation of concerns, i.e. small parts that each have a very limited responsibility.
The Moody example app uses this setup for its specific syncing needs. We hope that the sample code helps you understand how we intend for the syncing architecture to be put to use.
Throughout this chapter, the words local and remote have very specific meanings: local refers to things originating on a device, whereas remote refers to things originating on a server, which, in our case, is CloudKit. A local change, hence, is a change that originates on a device, e.g. a change caused by a user action, such as creating a new mood. Correspondingly, the term remote identifier refers to the identifier that CloudKit uses for a given object. Using the words local and remote throughout the code and this chapter simplifies a lot of the terminology.
This chapter will go less into detail and actual code samples and instead mostly try to convey the big picture of how to put together a code base that can sync local data with a backend. The Moody app on GitHub has the full code for a relatively simple implementation of this. Once you have read this chapter, the example project is a good place to look for more details.
Working with Multiple Contexts
In this chapter, we’ll look at more complex Core Data setups; in particular, we’ll explore how you can use Core Data in a multithreaded environment. Core Data allows for a multitude of different setups, so we’ll walk through the advantages and disadvantages of several of these approaches.
In part one of the book, we used the simplest version of a Core Data stack — one persistent store, one persistent store coordinator, and one managed object context — to build the example app. This setup is great for many simple persistency needs. If you can get away with it, use it, as it’ll save you from having to deal with the inherent complexities of concurrency.
In the previous chapter about syncing, we expanded this simple stack to use two managed object contexts — one on the main queue and one in the background — both connected to the same persistent store coordinator. This is the simplest and most battle-tested way to use Core Data concurrently. It’s also the approach that the NSPersistentContainer API facilitates out of the box. You should use this setup unless you have very specific reasons not to.
In this chapter, we’ll go into more detail about this default setup, but we’ll also discuss the tradeoffs of other possible setups to deepen the understanding of the Core Data stack. In the next chapter, we’ll then discuss some of the pitfalls related to using Core Data with multiple managed object contexts. But first, let’s take a step back and revisit Core Data’s concurrency model from the ground up.
Concurrency Rules
If you’re not familiar with the concepts of concurrency in general and dispatch queues specifically, we recommend you first read up on them before progressing further in this chapter. Two good resources to start with are Apple’s Concurrency Programming Guide and the objc.io issue from July 2013.
Core Data has a straightforward concurrency model: the managed object context and its managed objects must be accessed only from the context’s queue. Everything below the context — i.e. the persistent store coordinator, the persistent store, and SQLite — is thread-safe and can be shared between multiple contexts.
When you initialize an NSManagedObjectContext instance, you already specify the concurrency type with the init(concurrencyType:) initializer. When you use NSPersistentContainer to set up your stack, the container does this for you.
The first option, .mainQueueConcurrencyType, is what we used in part one of the book when using the container’s viewContext. As the name suggests, .mainQueueConcurrencyType ties the context to the main queue. The second option, .privateQueueConcurrencyType, ties the context to a private background queue, which Core Data manages for you. For example, when you call newBackgroundContext or performBackgroundTask on NSPersistentContainer, the returned context is initialized with the .privateQueueConcurrencyType option.
If you take only one thing away from this chapter, it should be this: always dispatch onto the context’s queue by calling perform before accessing the context or the managed objects registered with it. This is the most important rule for staying out of concurrency trouble.
Once you start working on multiple contexts, you’ll want to reconcile the changes at some point. This is done by observing one context’s did-save notification (see the chapter about changing and saving data for more details), dispatching onto the other context’s queue, and calling mergeChanges(fromContextDidSave:) to merge the changes contained in the notification’s userInfo dictionary:
let nc = NotificationCenter.default
token = nc.addObserver(forName: .NSManagedObjectContextDidSave, object: sourceContext, queue: nil) { note in
targetContext.perform {
targetContext.mergeChanges(fromContextDidSave: note)
}
}
Merging a did-save notification into a context will refresh the registered objects that have been changed, remove the ones that have been deleted, and fault in the ones that have been newly inserted. Then the context you’re merging into will send its own objects-did-change notification containing all the changes to the context’s objects:
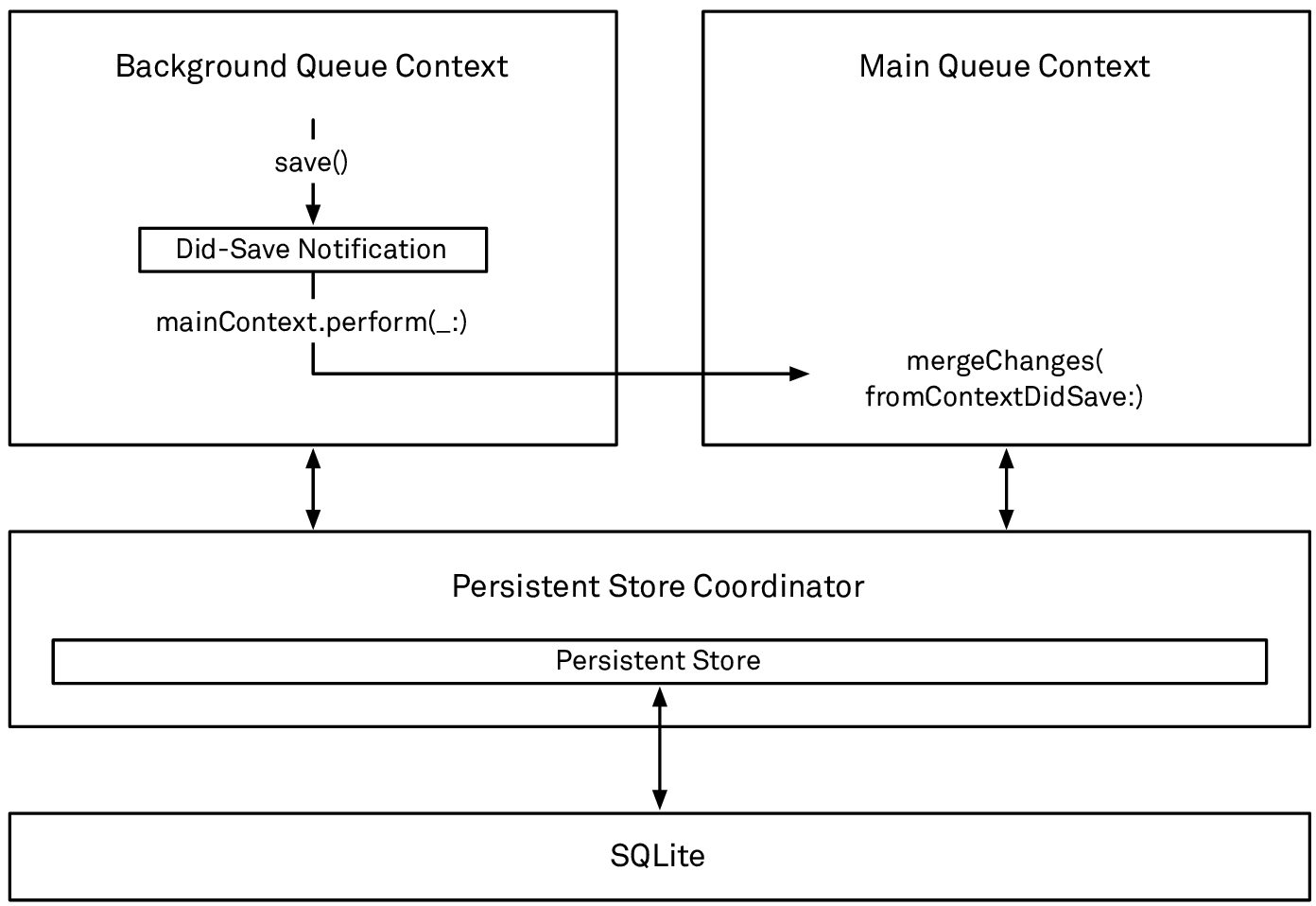
Reconciling changes between multiple contexts by merging their did-save notifications
This is the second-most important message of this chapter that will keep you out of concurrency trouble: totally separate the work you do on different contexts, and exchange information between them only through the merging of their did-save notifications — avoid wild dispatching between contexts like the plague.
The above message might be a bit too strong insofar as there are use cases where you might want to pass objects from one context to another, e.g. when doing a complicated search in the background. Nevertheless, it’s a good rule of thumb, and everything else should be a rare exception. For example, our sample app, with its syncing component, functions exactly in this way: all the syncing code works exclusively on its own managed object context, while the UI uses a separate managed object context. They only communicate with each other by merging the context-did-save notification.
Passing Objects Between Contexts
If you have to exchange objects between multiple contexts in a way other than by merging did-save notifications, you must use the indirect route: pass the object ID to the other context’s queue using perform, and re-instantiate the object there using the object(with objectID:) API. For example:
func finishedBackgroundOperation(_ objects: [NSManagedObject]) {
let ids = objects.map { $0.objectID }
mainContext.perform {
let results = ids.map(mainContext.object(with:))
// ... results can now be used on the main queue
}
}
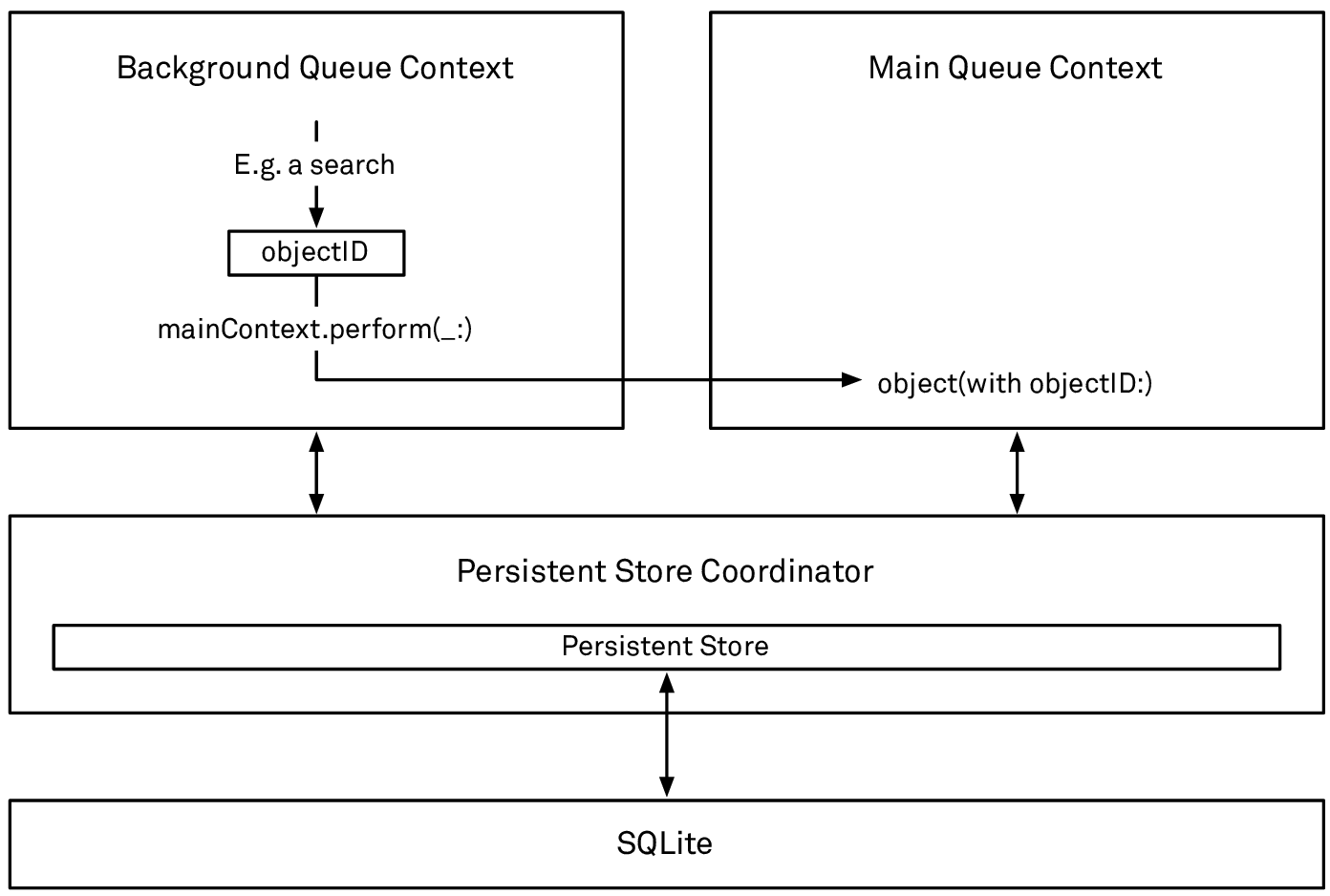
Handing a managed object from one context to another by passing its object ID
While it’s technically correct that you should only pass the object IDs to another context and re-instantiate the object there, you can use a technique that will guarantee to keep the objects’ row cache entries alive. This is useful because the target context can fulfill the object faults much quicker if the data is still in the row cache, compared to having to fetch it from SQLite.
You can achieve this by passing the objects themselves to the target context and extracting their IDs on the target context’s queue. However, it’s your responsibility to be very strict with this pattern — you must not use the objects in any way other than extracting their object IDs:
func finishedBackgroundOperation(_ objects: [NSManagedObject]) {
mainContext.perform {
let results = objects.map { mainContext.object(with: $0.objectID) }
// ... results can now be used on the main queue
}
}
In case the object ID is coming from a context connected to a different persistent store coordinator, you first have to reconstruct the object ID for the current stack from its URIRepresentation. The coordinator provides the managedObjectID(forURIRepresentation:) API for this purpose:
func finishedBackgroundOperation(_ objects: [NSManagedObject]) {
let ids = objects.map { $0.objectID }
separatePSCContext.perform {
let results = ids.map { (sourceID: NSManagedObjectID) -> NSManagedObject in
let uri = sourceID.uriRepresentation()
let psc = separatePSCContext.persistentStoreCoordinator!
let targetID = psc.managedObjectID(forURIRepresentation: uri)!
return separatePSCContext.object(with: targetID)
}
// ... results can now be used on the main queue
}
}
We’re using force unwrapping in this snippet for brevity, but you should always make your intent explicit using guard statements. Note that in this case, there’s no need to keep a reference to the objects themselves in order to keep their row cache entries alive; since the contexts don’t share the same persistent store coordinator, they don’t share a common row cache:
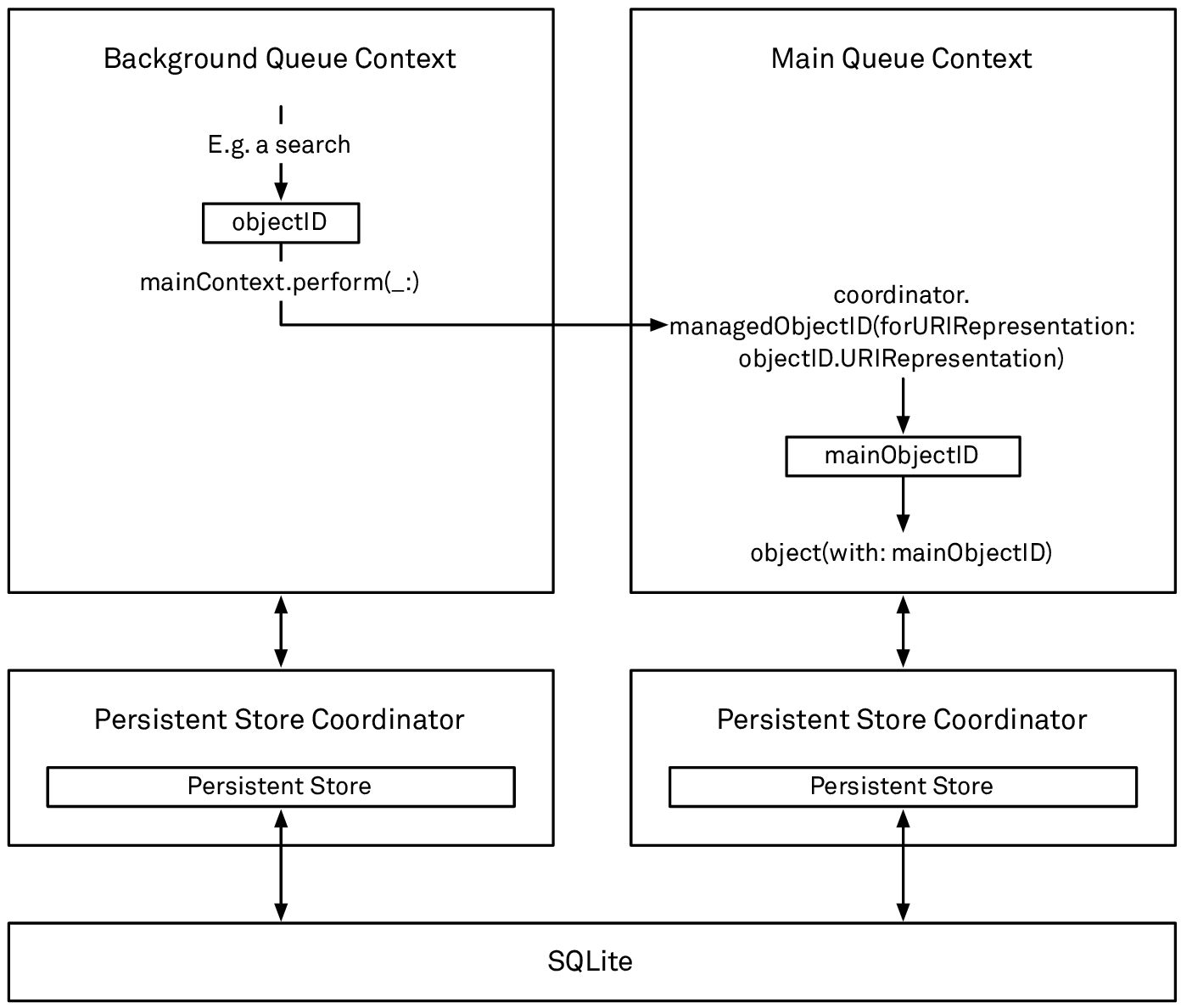
Handing a managed object between two contexts connected to different persistent store coordinators
Those are the basics of using Core Data correctly with multiple contexts. It’s not so complicated in practice if you stick to the rules: strictly separate the work on multiple contexts, always dispatch onto the context’s queue, and only pass object IDs between contexts.
Aside from these general rules, working concurrently with multiple contexts comes with complications — like conflicts and race conditions — that are inherent to concurrency itself. In the next chapter, we’ll explain in detail how to handle those cases.
We already briefly mentioned how merging changes between contexts works. We’ll explain this more in depth now before moving on to describe the advantages and disadvantages of several Core Data setups.
Merging Changes
Merging changes from one context into one (or multiple) other context(s) is relatively straightforward: we add an observer for Core Data’s context-did-save notification. Within this observer code, we dispatch onto the target context’s queue using perform. We then call mergeChanges(fromContextDidSave:) on this queue, passing in the notification as the argument.
During merging, Core Data will extract the object identifiers from the objects in the notification. It can’t use the objects themselves, since they must only be accessed on their own context’s queue. Once the target context has a list of object IDs, it’ll process the changes in the following way:
Inserted objects will be faulted into the context.
Note that these faults will be deallocated after the merging if nobody takes a strong reference to the inserted objects. You do have the chance to hold on to these objects when listening to the objects-did-change notification.
Updated objects that are registered in the context will be refreshed. All other updates will be ignored.
If an updated object has pending changes in the target context, the changes will be merged property by property, with the changes in the target context winning out in the case of conflicts.
Deleted objects that are registered in the context will be removed. All other deletions will be ignored.
If a deleted object has pending changes in the target context, it will be deleted regardless. It’s your responsibility to react accordingly if you’re currently using this object, like we did with the managed object change observer in the first chapter.
After merging is complete, processPendingChanges gets called and posts an objects-did-change notification, as described in the chapter on changing and saving data. (Core Data may post multiple objects-did-change notifications for one merge operation – you should make no assumptions about that.) By observing this notification, you get the chance to react to any of the changes that were merged into the context. Keep in mind that changes in the did-save notification that didn’t affect the target context (like updates of non-registered objects) won’t be present in the did-change notification.
Note that while Core Data posts the context-did-save notifications synchronously, causing our observing code to run before the call to save returns, the actual merge happens asynchronously because it’s wrapped in a call to perform. There’s a time window between the completion of the save operation and the merge of the changes into another context on a different queue. We’ll come back to this phenomenon when we talk about handling deletions in a concurrent environment in the next chapter.
When passing a did-save notification from one context to another, the row cache entries of the objects involved are guaranteed to stay around via the same technique we described above for passing objects between contexts: the notification strongly references the source context and all objects affected by the save. Since we’re using the notification object inside the closure passed to perform, the notification itself will be strongly referenced. Therefore, at the time of the merge, the affected objects are still alive, and as we mentioned in the chapter on accessing data, this guarantees their row cache entries will stay around as well. This is an important detail, as it saves round trips to SQLite later on when the faults inserted by the merging process have to be fulfilled.
Problems with Multiple Contexts
Once you start working with multiple managed object contexts at the same time, conflicts between the changes you make in those contexts can occur.
In part two, we mentioned conflicts during saving and how Core Data detects them with a two-step optimistic locking approach. In this chapter, we’ll go into more detail about how to use the predefined merge policies to resolve such conflicts, as well as how to define a custom merge policy.
We’ll also discuss how to pin a managed object context to a specific state of the store, how to avoid race conditions that can occur when deleting objects, and how you can enforce uniqueness requirements with multiple managed object contexts.
Predicates
A predicate encapsulates criteria that an object either matches or doesn’t. For example: the question or criteria “Is this person older than 32?” can be encoded into a predicate. We can then use this predicate to check if a Person object matches this criteria.
At the core of the NSPredicate class is the evaluate(with:) method, which takes an object and returns a boolean. Predicates have a special role in Core Data. Core Data can transform predicates into an SQL WHERE clause and hence use SQLite to efficiently evaluate the predicate against objects in the database without having to create objects in memory.
We use predicates to match a specific object or to filter a collection of objects to a smaller subset. Either way, it’s worth noting that we can use predicates both as part of a fetch request and directly on objects with the evaluate(with:) method.
In this chapter, we’ll walk you through both simple predicates and more complex examples. The discussion in this chapter focuses on predicates used with Core Data. Predicates can also be used independently of Core Data, but we won’t be going into details about that here.
You can find an accompanying playground for this chapter on GitHub.
Text
Storing text in Core Data is straightforward. Searching and sorting text strings, on the other hand, can be quite complex. Due to the intricacies of both Unicode and languages, the concept of two text strings being equal is very different from that of their underlying bytes being equal. And figuring out which string comes before another one is rather complicated too; it heavily depends on the locale at hand.
The Complexity of Unicode
Dealing with text is hard, and this chapter isn’t an extensive discussion of Unicode. For that, there are plenty of outside resources worth reading. We suggest objc.io’s article on Unicode as a good starting point, while the homepage of The Unicode Consortium is a great resource for all the scary details. For the purpose of this chapter, however, we’ll just look at a few examples to illustrate the problems of the domain.
Let’s assume that we have a City entity with a name property, and in our app, the user can search for a city by its name.
The 14th-largest city in France is Saint-Étienne. When a user types Saint-Étienne into the search field, we want to match this city with our search predicate. The problem is that the letter É can be represented in Unicode in two ways: either as the single code point U+00C9 (E with acute accent), or as the pair of code points U+0301 U+0045 (Combining acute accent followed by a regular E). From the user’s perspective, these are identical. Additionally, the user would expect to find the city even if the name is entered in lowercase, e.g. saint-étienne. And maybe the search string Saint Etienne should match too. The point is, these are all very different byte strings. They won’t be considered equal using a simple comparison, even though the user may expect them to be.
In some locales, a user would expect the Danish city Aarhus to be found when entering the search string Århus. The letter Å can either be represented by U+00C5 (A with ring above) or by U+030A U+0041 (Combining ring above followed by A). Meanwhile, in non-Latin scripts, we have to ask ourselves if the corresponding Latin text is supposed to match. Should the user be able to find the Chinese city of 西安 by entering “Xi'an?” And what about the apostrophe (U+0027) in this name? Should it be matched if the user enters a single end quotation mark (U+2019) as a search string?
The answers to these questions are highly domain specific. Solving all of these problems can get very complicated, but it’s essential to know which ones to solve and which ones not to solve for the given problem at hand. It may be important for your app that saint-etienne matches Saint-Étienne, but totally fine that Århus doesn’t match Aarhus.
Similar problems arise for sorting. Even with just the Latin script, things are more difficult than first meets the eye. When looking at individual letters, it’s obvious that B comes after A. But things can be different when looking at complete words. And the sort order depends on the user’s locale — which language the user’s operating system is set to use.
Just within Germany, there are two sort orders for the letter ö: it’s considered equal to either o or oe. In German, Köln is sorted before Kyllburg. In Swedish, however, the letter ö follows all other letters so that Sundsvall would be sorted before Södertälje.
A Danish user would expect the cities Viborg, Ølstykke-Stenløse, and Aarhus to be in this order. This is because the letter Ø follows the letter Z, and the double A is semantically equivalent to the letter Å, which is the last letter in the Danish alphabet.
When mixing scripts, should Москва be ordered before or after all names in the Latin script? Or should it be intermixed, i.e. Москва next to Madrid?
Again, the answer depends on the domain, i.e. what problem the app is trying to solve.
It’s also important to note that in programming, there are situations where we’re using text strings that aren’t going to be visible to the user. If a text string is just an identifier or a key not visible in the UI, we may not want art to match Art.
Model Versions and Migrating Data
We already mentioned in the relationships chapter that opening an SQLite store file with a data model that doesn’t match the contents of the database will cause an exception. This is where versioned data models and migrations come in. As an app grows and new features are added over time, the data model must adapt to the new requirements, e.g. by adding new attributes. Rather than simply changing the data model in place, we create new versions of the model and migrate existing data from the old model to the new model. In this chapter, we’ll go into details about how this works.
This chapter refers to a separate example project on GitHub where we take the Moody data model through a series of migrations, showcasing the different techniques available. The project contains a test target, which tests the migration of pre-populated SQLite stores by comparing the results to hardcoded test fixtures. We’ll talk more about the test setup later on.
Before we dive into the topic of migrations itself, we’d like to encourage you to consider whether or not you really need to migrate existing data. Migrations add an extra layer of complexity and maintenance work to your application. For example, if you’re using Core Data only as an offline cache for data from a web service, you might get away with deleting the local data, creating a fresh store, and pulling the data you need from the backend again. Obviously there are many cases where you do need to migrate, but it’s still worth thinking about this before you get started.
Profiling
We already talked about many aspects of ensuring great performance from Core Data in the dedicated chapter about performance. In this chapter, we’ll focus on how to profile Core Data to determine exactly where performance bottlenecks occur and how you can use this information to improve your code.
The techniques demonstrated in this chapter are not only great for profiling your app; they can also help when you’re trying to understand what’s happening in the Core Data stack. For example, we used the first tool, Core Data’s SQL debug output, a lot during the process of writing this book.
Relational Database Basics and SQL
The default store of Core Data is the SQLite store. Most of the concepts of Core Data are designed around how the SQLite store works, and in this chapter, we’ll take a closer look at them. You don’t need to know everything we discuss here in order to use Core Data, but it’s very helpful when trying to understand its inner workings.
A word of warning: this chapter will skip some details, and it presents relational databases in the way they’re used by Core Data. As such, the focus is on understanding the aforementioned things. In particular, we won’t go into details about creating tables and inserting data. These may seem like basics, but they’re not at all important for our purpose.